Here on the Data Engineering Team at Wealthfront, we have recently been building out our Near Real-Time computation platform to provide the ability to ingest, process, and serve data to our backend and frontend services with very low round trip latency. This platform will be the backbone for a multitude of applications for us including scaling our existing systems for more clients and enabling new features in Path.
Path, which launched almost a year ago, is our comprehensive financial planning and investing solution. As part of the product, we allow our clients to link various external financial accounts so we can use this information to provide clients with an overall picture of their financial well-being and provide better advice. One of the very first streaming pipelines which we created is a pipeline which, using a model trained offline, classifies and aggregates a client’s transactions to be able to give them a better picture of their saving and spending habits.
In order to perform this calculation, we stream clients’ transactions along with other account update information streams. The transactions are classified, then joined with the other streams, and the resulting output streams either update the savings rate on the client’s dashboard or populate it for the first time if the client has just linked the account. We wanted the general architecture of the solution to look something like this:
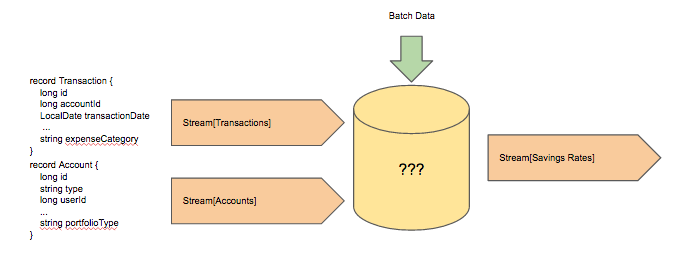
Clearly, to enable this kind of streaming computation we needed some sort of stream processing engine, and we chose Spark Streaming. We use batch Spark pipelines as our primary offline computation engine, and Spark Streaming enables us to share code between our batch and streaming computations and reduce the code complexity of our lambda architecture.
{kind=link}
Spark Streaming offers many of the great infrastructure fault tolerance features which we have come to appreciate in Spark such as resilience to lost nodes, but we also quickly developed use cases that require some additional attention to application errors. In a batch pipeline, an unhandled application error such as an NPE or other runtime exception causes the pipeline to fail, alerting us to the failure in the process. The same does not apply in a streaming pipeline, as we’d like to be able to continue processing data for clients which may be unaffected by the failure.
Consider the following piece of code:
val input: DStream[Long] = … input.map(x => if (x % 10 == 0) 1/0 else x) .forEachRDD(rdd => rdd.saveAsNewApiHadoopFile(....) )
This short application would not fail outright, and the only place where errors would surface would be the Spark log as WARN level entries. The first step in improving our reactivity to this sort of problem was to add handling and alerting around our output writing. While unintuitive, catching errors at write time works because Spark computation is lazy; any runtime errors caused by evaluating code occur only when we write output. This was accomplished by adding a simple try/catch wrapping around our SaveAsNewApiHadoopFile calls; this enabled us to alert on micro-batch failures and page on elevated failure rates.
We soon realized that while this degree of handling was good enough for most applications, it wasn’t for this one because we wanted to prevent showing incomplete data to clients. When we process a stream of transactions, all the transactions for the client’s account must be contained in the microbatches to prevent a client’s dashboard to remain unpopulated or cause the displayed savings rate to be erroneous. We therefore decided that if a certain microbatch failed in this streaming pipeline, that we would need to be able to know which client’s experiences could be affected. This seemed at first a bit counterintuitive – how would we be able to know which clients would have been affected by the result of the microbatch if we could not compute the result?
Client transactions, as they are streamed in, trigger updates to the client’s savings rate. When we looked at it from that perspective we realized that if we wanted to know which clients’ dashboards would have been affected by a certain microbatch failure, we just needed to figure out which transactions were contained in that microbatch; given a transaction, we would be able to determine which accounts were affected by joining with the accounts which we have already processed. This gave us something concrete to work with, and now that we knew what we were looking for, we just needed a way to find those transactions.
The solution lies in the information that Spark keeps under the hood, namely the underlying DAG of tasks. For reasons of fault tolerance, each RDD stores pointers to the metadata of its entire ancestry. Looking at the example below (where failed RDDs are colored red and successful RDDs are colored green) we see that there are two input RDDs which are transformed, then joined together, and then the result of the join is further transformed. An application failure occurs in the map step between RDD 1.2 and 1.3 which causes all downstream RDDs from 1.3 to also fail.
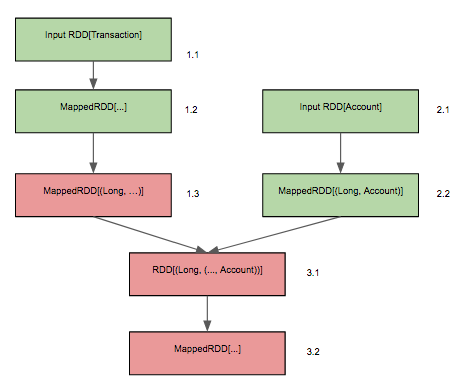
In order to be fault tolerant to infrastructure failures, Spark stores pointers from each RDD to its ancestors, i.e. RDD 3.1 stores pointers to RDDs 1.3 and 2.2, this allows Spark to retry computation on a failed RDD and potentially recover in situations such as a lost node. This also enables us to trace backwards to find the ancestor RDDs of our output which had not yet failed for which we would still access the information they contained. Rather than subclass the RDD class, we chose to simply wrap it in an implicit class:
implicit class RDDWithParent[K](rdd: RDD[K]) { def getParentRDDS(): Seq[RDD]] = { rdd.dependencies.map(_.rdd) } }
Given that we know the type parameter of the records we are looking for in the ancestry of an RDD we are able to traverse back through lineage of the microbatch output finding the transactions we are interested in by performing a BFS on the ancestry graph and matching on runtime class for the inputs. The code to accomplish this should look familiar:
implicit class RDDWithParent[K](rdd: RDD[K]) { def getClosestNonFailedAncestorMatching[T: ClassTag](clazz: Class[_]): Option[RDD[T]] = { val searchQueue: mutable.Queue[RDD[_]] = mutable.Queue() var maybeMatchingRDD: Option[RDD[T]] = None searchQueue.enqueue(rdd) while(searchQueue.nonEmpty && maybeMatchingRDD.isEmpty) { val currentRdd = searchQueue.dequeue() if (currentRdd.elementClassTag.runtimeClass.equals(clazz) && Try(currentRdd.isEmpty()).isSuccess) { maybeMatchingRDD = Some(currentRdd.map(_.asInstanceOf[T])) } for (parent <- currentRdd.dependencies.map(_.rdd)) { searchQueue.enqueue(parent) } } maybeMatchingRDD } }
When a microbatch fails, we are able to determine which transactions were dropped, and therefore which clients’ dashboards are affected. This enables us to let the services which consume our data know when their current state may be stale or incorrect to provide better messaging to our users.
Naturally, this solution is not applicable to all use cases; tracing back through the lineage of the RDD can increase the latency of a system, and depending on how we want to serve the failures, this can require storing more state in memory in the pipeline. Nonetheless, we have found situations where this slightly unusual solution has worked quite well for us.
Disclosure
Nothing in this blog should be construed as tax advice, a solicitation or offer, or recommendation, to buy or sell any security. Financial advisory services are only provided to investors who become Wealthfront Inc. clients pursuant to a written agreement, which investors are urged to read carefully, that is available at www.wealthfront.com. All securities involve risk and may result in some loss. For more information please visit www.wealthfront.com or see our Full Disclosure. While the data Wealthfront uses from third parties is believed to be reliable, Wealthfront does not guarantee the accuracy of the information.