Here at Wealthfront, our mission is to democratize access to sophisticated financial advice. One of the ways we accomplish that is by applying data processing technologies to financial services. In this two-part blog post we will describe how our near-real time data platform is built to support continuous deployment in order to allow us to ship new features quickly and safely. Part 1 of this series will give a high level overview of the data platform at Wealthfront and describe how we deploy and track Spark Streaming jobs for continuous delivery. In Part 2 we will show how we coordinate the serving layer and summarize how the whole system works together.
The Data Platform at Wealthfront
The data platform at Wealthfront is modeled on Lambda Architecture which consists of two computation layers — batch and real-time — and the serving layer. We have chosen Spark as our computation layer framework which provides an API for both batch and stream processing. Our serving layer is a homemade NoSQL database written around cdb and rocksdb.
In accordance with Lambda architecture, our batch computations are responsible for providing an all-of-time historical view of the data. Many of these computations are scheduled to run daily at midnight, processing all of our historical data. Our real-time computations are run throughout the day, providing up-to-date transformations of new data after the last batch run. The results of batch and real-time computations are loaded into our serving layer (i.e. database) which exposes a merged view of the data.
Redeploying Spark Streaming
The main issue we had to tackle for continuous deployment with Spark Streaming is deploying new code with no downtime during job transitions. A simple approach to redeploying a code change to a Spark Streaming job would look something like this:
- Build the code, package into a jar
- Deploy the jar to the Spark cluster
- Shut down the originally running Spark Streaming job
- Start up a new Spark Streaming job (now running on new code)
This approach certainly does work and we had been redeploying our jobs in this way for about a year. However, the downside is that the downtime between steps 3 and 4 can be long and during this downtime, new incoming data is not being processed which impacts data freshness. The main reason for this downtime is à la Lambda Architecture, when we restart a streaming job, it has to reprocess all new data since the last batch computation. It is technically possible to restart a stream computation to pick up where the last left off, but in practice using old data (or in the case of new features, empty data) can result in erroneous results which for us is unacceptable.
Taking a page out of Kappa Architecture (which ironically is a criticism of Lambda Architecture), we designed our system to support reprocessing so that when we deploy a new version of a Spark Streaming job, we start another instance while leaving the old instance running. Once the new instance has caught up to the old instance, we shut down the old instance.
In order to coordinate between jobs, we set up a service called StatusTracker that would be responsible for tracking the status of jobs and coordinating the shutdown process. Each Spark Streaming job instance is assigned a unique ID and will publish its progress to the Status Tracker. Once the Status Tracker has determined that a new instance of a job has caught up, it will shut down the old instance. The architecture looks like this:
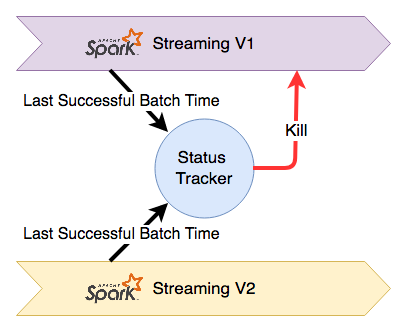
Spark Streaming is not a pure real-time stream processing framework and instead operates by scheduling micro-batches of data for processing. These micro-batches are assembled based on new data in the input stream which means we only need to know the scheduled time of the most recently completed micro batch to infer the progress of a streaming job. If the most recently completed micro-batch of the new job has the same scheduled time to that of the old job, we know that they have processed data to the same point in time and the new job can be considered “caught-up”.
Conveniently, Spark Streaming provides an interface that allows you to register a listener that will be called after each completed micro-batch. This interface also provides the scheduled time of the micro-batch which we include in our update message so that the StatusTracker can calculate the progress of the job. This micro-batch listener/progress updater looks like this:
Tracking Job Status
In the StatusTracker, each job instance can be in one of the following states:
- CATCHING_UP: Job running, but has not caught up yet
- LATE: Job has been running for X duration, but still has not caught up
- PRIMARY: Job has caught up and is now the primary instance
- KILLED: Job is scheduled for shutdown
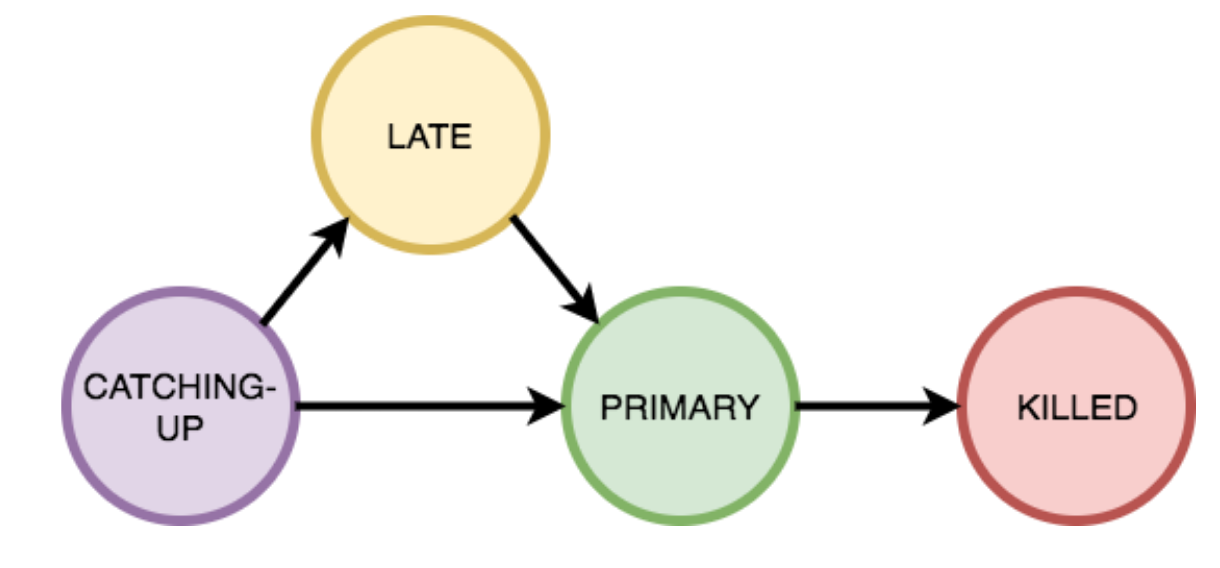
Every job starts in the catch-up state as it re-processes historical data. While this job is catching up, the original instance of the job (which is in the PRIMARY state) is still running and processing data. The jobs are essentially in a race where we are waiting until the new job catches up to the old job. It is possible, however, that the new job never catches up to the old instance if there is new code introduced that has degraded the job performance. We would want to know if this situation happens and so we introduce a state (LATE) in which the job is observed to have exceeded some threshold of time without successfully catching up. This state results in an alert to our engineers so that they can investigate if there is a performance regression.
At some point if the new job successfully progresses to the same data as the old job, two state transitions happen: the new job instance enters the PRIMARY state, while the old instance enters into the KILLED state. Only one job instance can be in the PRIMARY state, and the data from this instance is used to serve queries in the serving layer. A job instance in the KILLED state is scheduled to be shut down.
As a result, the StatusTracker has the following responsibilities:
- Receiving last batch time for each job instance and updating job state
- Shutting down older jobs in a KILLED state
- Notifying the serving layer to serve queries off data in the PRIMARY state
- Monitoring and alerting for any LATE or KILLED jobs
When the StatusTracker receives a new update, it will first check if the job that sent the message is already in the KILLED state. This triggers an alert to an engineer since a killed job should not be sending any more updates and likely has to be force killed. If the job is not KILLED, the StatusTracker makes all necessary state transitions based on the new update message. Afterwards it shuts down any jobs in the KILLED state, alerts if any jobs have entered the LATE state, and notifies the serving layer about any jobs that transitioned to the PRIMARY state.
Next up
In this first part of the blog post series, we gave a high level overview of the Lambda Architecture-based data platform at Wealthfront. We also detailed how we track and coordinate Spark Streaming jobs in order to eliminate processing downtime during redeployment. In the next post we will be moving downstream to describe how we coordinate the output data in the serving layer and wrap up with a summary of how everything works together. Stay tuned!
Wealthfront prepared this blog for educational purposes and not as an offer, recommendation, or solicitation to buy or sell any security. Wealthfront and its affiliates may rely on information from various sources we believe to be reliable (including clients and other third parties), but cannot guarantee its accuracy or completeness. See our Full Disclosure for more important information.
Wealthfront and its affiliates do not provide tax advice and investors are encouraged to consult with their personal tax advisor. Financial advisory and planning services are only provided to investors who become clients by way of a written agreement. All investing involves risk, including the possible loss of money you invest. Past performance does not guarantee future performance.