Every engineering organization faces the problem of how to ensure that things are done right. At Wealthfront, our appoach is a safety net of extremely thorough automated testing that guides the engineer to do the right thing.
- Automation is consistent. It doesn’t skip a code review because we’re in a hurry. It doesn’t fail to notice a problem.
- Automation is leveraged. When we write a bug detector or monitoring tool, those will automatically apply to all future code we write.
- Automation is impersonal. Our build server doesn’t think it’s being pedantic failing a build because you have ugly formatting, and it’s a lot easier psychologically to have a computer give you a list of your failings than a colleague.
The automation is roughly divided into three stages. Unit tests ensure that your code does what you intended it to do. Static analysis ensures that your code is doing things the right way, without doing anything in a dangerous way. Monitoring ensures that your code is still working in production.
If this were a post about TDD, I’d differentiate between unit, functional and integration tests, but in this case it’s fine to lump them anything that tests whether your code is doing what you intended together as unit tests. We test using JUnit. It has good integration with our other tools — Eclipse, Ant and Hudson. We use jMock for mocking, and HSQLDB in-memory database with DbUnit for testing persistence.
 |
| assertBigDecimalEquals |
We also have a pretty well developed set of internal helpers that help cut out the boilerplate. To start with we have a centralized Assert class offering helper methods like assertBigDecimalEquals and assertXmlEquals for objects that assertEquals doesn’t behave well on. In these methods, we relax our habits of using very strict types. While in production code we’d be appalled to be passing around a double just for the purpose of turning it into a BigDecimal, inside a test, this makes things much more readable.
Since testing persistence and clearing the database between tests is easy to get wrong, we encapsulate this inside an abstract PersistentTest. Specific tests just need to indicate which groups of entities they need defined and everything will work. Extending PersistentTest also allows you to use Guice to inject object repositories into your tests rather than creating them.
Many of our entities have long chains of dependencies in terms of a Position is composed of Lots that belong to Portfolio and so on. To simplify these we have factory classes using the builder pattern that can create the object either detached or within a Hibernate session. These aren’t any deep voodoo, just a collection of convenience methods and builders that ensure if you just need a Position, it can create some appropriate related data to make things work.
Together, all of these helpers make it easy for engineers to write tests that read like documentation. Everything not central to what’s being tested is abstracted away, and the test focuses on “if I have x, and I do y, then I expect to have z”.
Of course, none of that is going to guarantee that tests get written. In this we take a strategy of “trust, but remind.” We trust the engineer to make sure that the code gets tested to an appropriate level — a tool used internally to get some statistics obviously needs less testing than our code that calculates the appropriate trades based on a manager’s model portfolio. We remind people to write tests in two ways. First, any check-in of a new class in src that doesn’t add a new test sends an email to the team saying “Hey! I (kevinp) forgot to add tests for new java or scala class in revision: r42626 or add #testnotneeded to the commit message. I’m going to reply to this thread in a bit and explain why.” Secondly, we have a test that does static analysis to ensure that all Queries either have a test or are listed as exceptions. Queries are the functional building block that compose our services.
This minimal oversight ensures that we don’t stray too far from testable code. It’s immediate and it forces the author to make a choice of “this is somehow hard to test but also really simple so it doesn’t need testing, so I’ll add an exception and say #testnotneeded” or “fine, I’ll go write a simple test that exercises the simple expected path through the code”. Writing any sort of test at least ensures that the code doesn’t have strange dependencies on hard coded paths or global state, documents the expected behavior, and provides something to build on later when a bug gets found or behavior needs to be changed.
We do two types of static analysis. The first type is a collection of tests based on the declarative test runner from Kawala (our open source platform). These run as part of the main build and a failure breaks the build and stops deployments. The second type are two open source static analysis tools, FindBugs and PMD. These run as part of a separate analytics build and does not prevent deployments. It still sends you nagging email until it’s fixed, of course. The goal is to detect whether you’re doing things the right way. Presumably since your code has passed all the unit tests, it works, but maybe it has more subtle bugs or is likely to be unmaintainable in the future.
Dependency test tries to enforce good package structure. It lets you express that, for example, everything is allowed to depend on com.wealthfront.utils, but only certain packages are allowed to depend on com.wealthfront.trading.internal. Visibility test lets us annotate methods or classes as @VisibleForTesting to express the difference between “this is public, anyone can use it” and “this is public because I need to access it from another package in a test”.
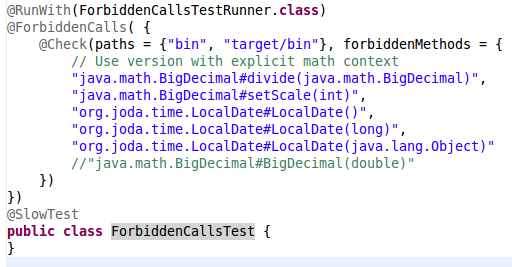 |
| ForbiddenCallsTest |
JavaBadCodeSnippetsTest, ScalaBadCodeSnippetsTest, and ForbiddenCallsTest look for things that are so error-prone or so likely to be a bug that you should never use them. For example, we forbid importing java.net.URL because of its surprising hashCode and equals behavior. The only exceptions are a few places dealing with networking or the class loader.
The snippets tests are source based and run using BadCodeSnippetsRunner. These match on regular expressions, and they also enforce some style rules, for example putting a space between “if”, “for” or “while” and the opening parenthesis. This isn’t the main purpose of the test, but if you are going to adopt a coding standard, and your tools make it easy to enforce, then go ahead and enforce it.
ForbiddenCallsTest is bytecode-based, which allows us to do things like disallowing org.joda.time.LocalDate.toDateTimeAtStartOfDay() (dangerous because it implicitly uses the default time-zone) while allowing org.joda.time.LocalDate.toDateTimeAtStartOfDay(DateTimeZone).
This isn’t as easy to use out of the box as PMD or FindBugs, but you can use it without much effort. DeclarativeTestRunner lets you set up a bunch of rules that will be matched in turn against a set of instances, and any failures will be reported. Since it’s a generic framework for writing declarative tests that iterate over a series of files, it’s more flexible than tools like PMD that only expose a simplified version of the AST. On the other hand, you can’t easily duplicate some of the non-local tests that FindBugs can do like checking for inconsistent synchronization.
Some of the tests we have using this framework are more specific to our project. The QueriesAreTestedTest I mentioned above uses DeclarativeTestRunner, as do a test ensuring that classes annotated as JSON entities are actually marshallable, tests that all methods used by the front end (a separate jRuby on Rails project) as still present with the same signatures, and tests that no entities (Hibernate or JSON) attempt to @Inject any dependencies.
Since all of these tests will fail the build, we have a test suite defined containing 10 “pre-commit tests”. It’s usually only necessary to run the tests for whatever you are working on and the pre-commit tests, and you can be about 95% sure of not breaking the build. It’s not actually necessary to run the full 7000-test suite before every commit.
 |
| Hudson Analysis Plugin |
FindBugs and PMD are two widely used bug pattern detectors. To some extent they overlap, but they detect slightly different things so it’s worth using both. We added FindBugs first and PMD afterwords. We haven’t yet eliminated all PMD warnings. We have about 200 remaining, mostly issues that don’t affect the correctness of the code, like “collapsible if statements” meaning that you can combine the conditions into a single statement to make the code clearer. It’s a perfectly valid point, but not really a high priority to fix.
FindBugs and PMD (and several others) integrate very well with Hudson CI. The Analysis plugin will display charts of high, medium and low priority warnings, changes from the previous build, and fail the build based on either absolute thresholds or when the number of warnings increases.
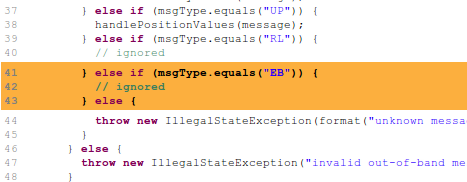 |
| Good code that triggers a PMD warning. |
Resolving failures or warnings reported by any kind of static analysis doesn’t always mean changing your code; often it means adding exceptions. I’ve seen people recommend elaborate systems involving taking a vote on how important each warning is and whether the rule should be excluded, but this seems like overkill. At Wealthfront, exceptions are easy to add. Just open up the file and add an exception, or annotate with @SuppressWarnings, as appropriate. This goes along with “trust, but remind”. The static analysis is your helper, not your master. Making it easy to add exceptions lets us be strict with the rules. Being strict with the rules gives the engineer a little reminder when they stray into dangerous territory. It forces you to think “hmm… do I really want to make our core data model have a dependency on this vendor specific package?” If you make exceptions too hard to add, everyone will preemptively exclude any rules likely to need exceptions.
Testing doesn’t stop when code gets to production. I’ll save the details for another post, but the key is everything is automated and there’s no human tasked with finding the problems. A human is only asked to investigate once the system has found some reason to suspect a problem. Machines are very good at tedious repetitive tasks like checking a service is up, or checking that a report got generated. Humans are good at exercising judgment whether something reported is an actual problem, as long as the volume of alerts is manageable.
Unit tests verify your code does what you intended it to do. Static analysis ensures you aren’t doing it in a way that will cause problems down the line. Monitoring ensures that your code is still actually doing the right thing once it’s in production.
Combined, these tools allow us to keep going forward with improvements without needing to stop to fix bugs or horribly flaky code too often. Of course, we still need to reorganize code because it’s grown to do something other than what it was intended, and that’s where the automation really shines. All the folk wisdom around the office of “oh, everyone knows you can’t use a static SimpleDateFormat” is embedded in code, so we avoid making the same mistake twice.