Data drives everything we do here at Wealthfront, so ensuring it’s stored correctly and efficiently is of the utmost importance. To make sure we’re always as informed as possible we gather data from our online databases very frequently. However, this has the unfortunate side effect of creating a large amount of small files, which are inefficient to process in Hadoop.
The Small Files Problem
Typically, a separate map is created for each file in the Hadoop job. An excessive amount of files therefore creates a correspondingly excessive amount of mappers. Further, when there are many small files each occupying their own HDFS block an enormous amount of overhead in the namenode is incurred. The namenode tracks where all files are stored in the cluster and needs to be queried any time an application performs an action on a file. The smooth performance of the namenode is thus of critical importance as it is a single point of failure for the cluster. To make matters worse, Hadoop is optimized for large files; small files cause many more seeks when reading.
This set of issues in Hadoop is collectively known as the small files problem. One good solution when pulling small files stored in S3 to a cluster is to use a tool such as S3DistCp, which can concatenate small files by means of a ‘group by’ operator before they are used in the Hadoop job. We, however, cannot use this tool for our data set. Our data is stored in avro files, which cannot be directly concatenated to one another. Combining avro files requires stripping the header, which requires logic that S3DistCp does not provide.
A Consolidated Files Solution
To solve this the small files problem, we periodically consolidate our avro files, merging their information into a single file that is much more efficient to process. For data that is taken hourly, we take the files for each hour of the day and merge them into a single file containing the data for the entire day. We can further merge these days into months. The monthly file contains the same data as the set of all the hourly files falling within its span, but it is contained in a single location instead of many. By switching from using the original hourly files to monthly ones, we can cut down the number of files by a factor of 720.
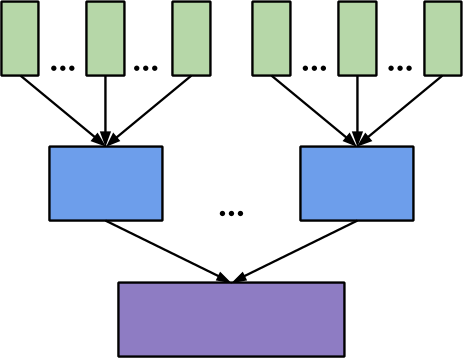
Hours combine to form a day, days combine to form a month*.
*Wealthfront is aware that there are more than 3 hours in a day and more than two days in a month; this is a simplified visualization
We must ensure that we do not take this too far however. Consolidating already large files can begin to reduce performance again. To this prevent this, the code only consolidates the files if the combined size does not exceed a specified threshold. This threshold is chosen based on the HDFS block size; there is no gain to be had from a file that already fills a block completely.
Selecting Files For Computation
This creates the new challenge of dealing with files that span different durations. In general, when requesting data across an interval of time we want to choose the fewest amount of files that will give us the desired dataset without any duplicates. Consider the following diagram representing a collection of files arranged chronologically. We wish to fetch only the data falling between the red lines, and use as few files as possible.
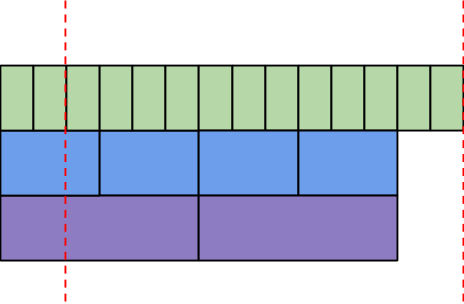
Our approach is a greedy algorithm which takes files spanning the largest amount of time first, and considering progressively smaller intervals. In this case, we first consider the monthly intervals. We eliminate the first month because it includes data outside our requested timeframe.
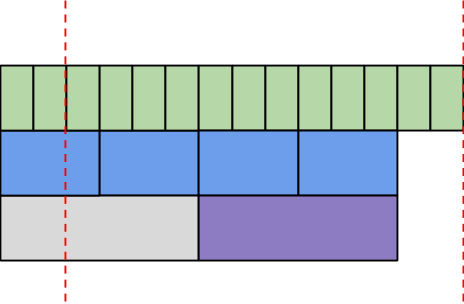
We next consider the days. We first eliminate the day not fully in our timeframe. We also eliminate the days that overlap with our previously selected month.
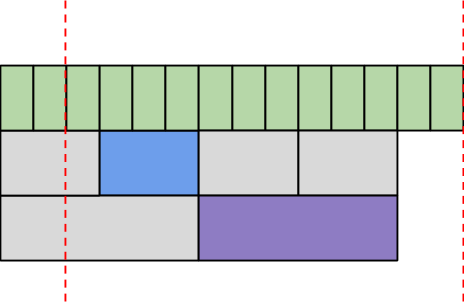
Applying the same action to hours gives us our final choice of files to use.
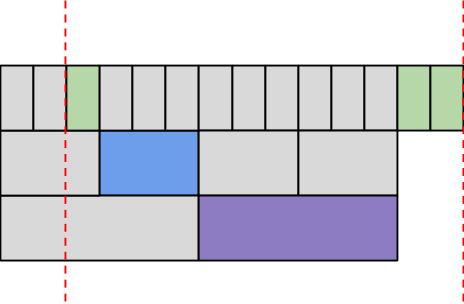
Note that the entire interval is covered, there is no duplication of data, and a minimum number of files are used. We fetch the same data that would have been retrieved by taking each hourly file in our interval, but it arrives in a format that is much more fit to process in Hadoop.
Handling Outdated Files
The danger in creating consolidated files lies in the fact that the derived file will become outdated if the source files beneath it are changed. We protect ourselves against this risk by validating consolidated files when they are requested for use. If there is a file spanning a smaller interval time that was updated more recently than the file meant to encapsulate it the underlying data has changed since the consolidated file was created. We ignore the outdated file and go down to the next lower level of smaller files. We also log an error noting the consolidated file is outdated so it may be recreated and made fresh again.
Results
We find that this consolidation has an enormous impact on performance. Our first test case was a job that previously operated on a few years worth of data, bucketed into files by hour. When attempting to use this multitude of small files, the cluster would fail after more than 2 hours when it ran out of memory. With the consolidated files, the same cluster successfully completed the job in 1 hour 15 minutes.

This strategy comes with the tradeoff of significantly increased disk space usage in our cloud storage system as we store a full copy of our data for each level of consolidation used. In our case, this is a very small penalty compared to the enormous gains in performance.
Our infrastructure is extremely important to us at Wealthfront. We are constantly working to ensure that our systems can support the rapid influx of new clients. File consolidation is just one of the many ways we keep our infrastructure as efficient and robust as possible.