What is bandit testing?
You’ve probably heard of A/B testing, but you may not be familiar with its alternative — bandit testing. As a reminder, an A/B test consists of one or more variants and a “control”. The control should replicate the existing experience, if applicable. Each variant will result in a different experience for the user, and the goal of the test is to measure which variant performs the best. For example, let’s imagine we want to gauge interest in our Investment Accounts versus our Cash Accounts. We run an A/B experiment with two variants, the “Control” banner advertising investing and “Variant A” banner advertising our cash account:
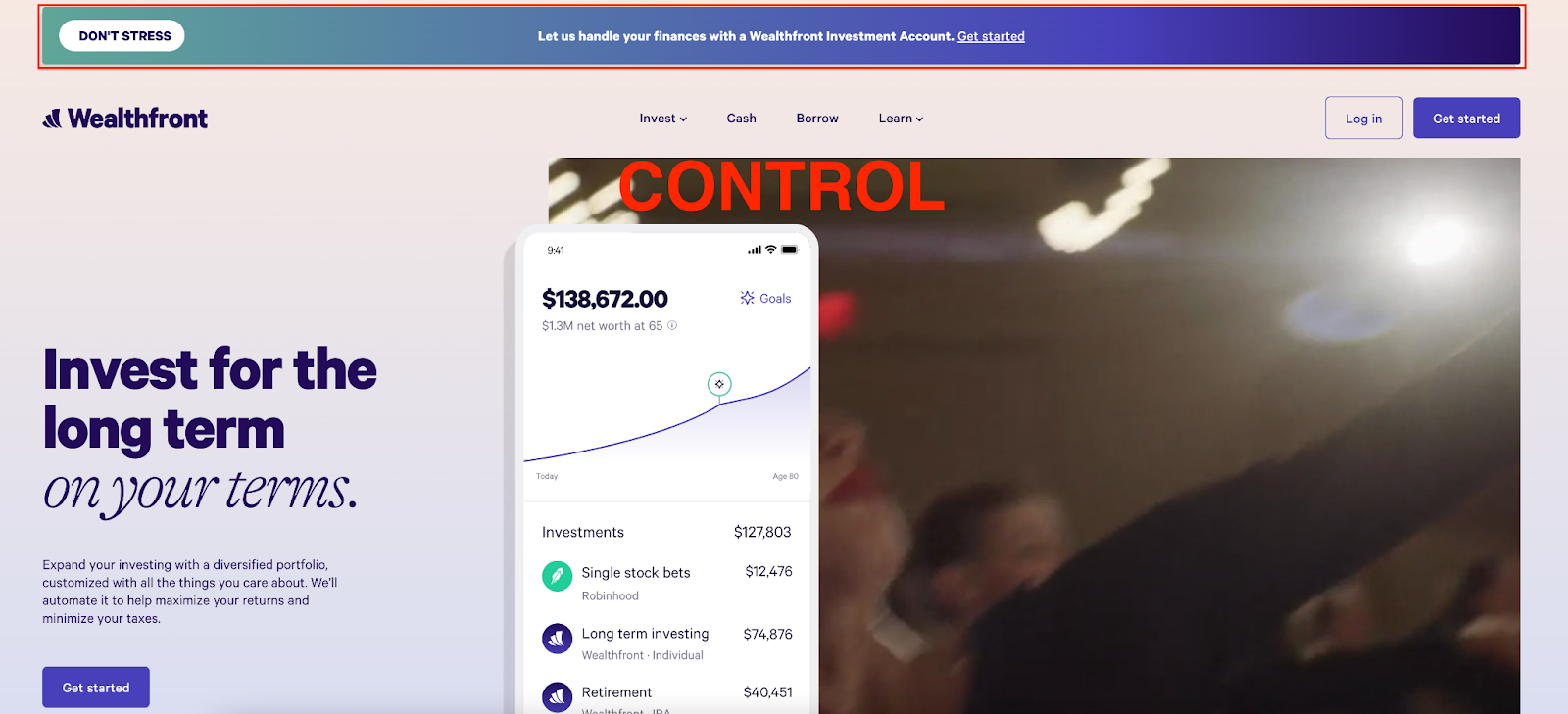
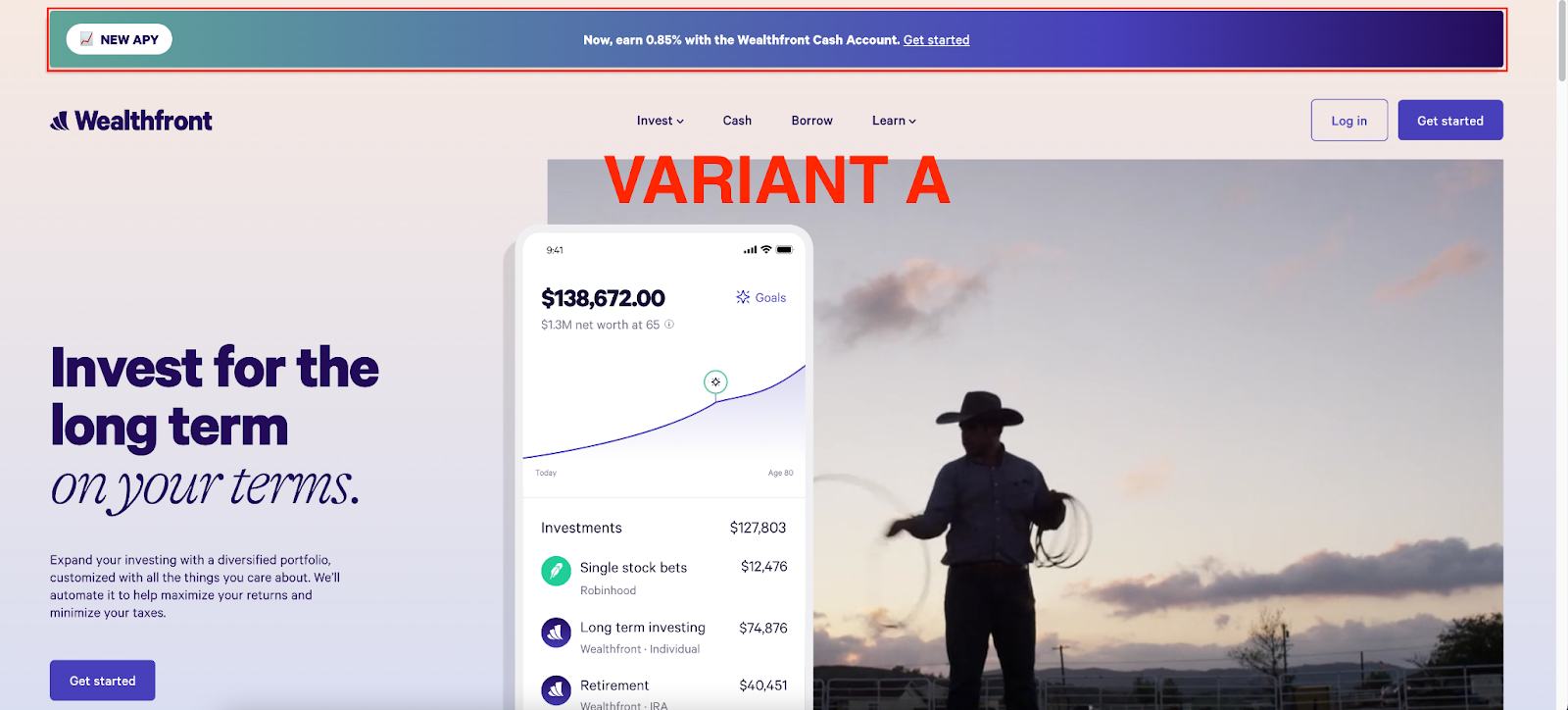
We ramp each to 50% weight, so that half of our users see the control and the other half see the variant. Then, we wait until statistical significance is achieved. Waiting for statistical significance could take days, weeks, or months depending on the volume of traffic for the experiment. Finally, we measure the performance of each variant and decide which one we should move forward with.
There’s one critical flaw with A/B testing, it only focuses on exploration (measuring performance and impacts), not exploitation (optimizing performance). Even if Variant A is performing ten times better than the investing control, the control is still shown just as frequently until we achieve statistical significance and resolve the experiment. That’s where bandit testing comes in. In a bandit testing experiment, we can take advantage of both exploration and exploitation at the same time. Instead of keeping the variants at equal weights throughout the duration of the experiment, they are adjusted dynamically based on how they are performing. Below is a simulation of a bandit experiment with four variants A, B, C, and D with 30%, 29%, 28%, 27% success rates (+/-2%) respectively:

You can see that as the experiment progresses, the best performing variants take up a larger share of the total variant weight, so they are shown more often. It also reduces cumulative regret, which is the number of conversions lost when comparing the assigned variant to the highest performing variant. So if 100 users are shown variant D, that’s 3 points of cumulative regret (.3 – .27) * 100 = 3. Below is a graph of cumulative regret for the simulated bandit test plotted against the cumulative regret if it had been run as an A/B test:

As you can see, the A/B cumulative regret is linear throughout the duration of the experiment, because the variant weights do not change. However, the bandit cumulative regret is asymptotic as the best performing variant approaches 100% of the total variant weight.
How does it work?
To implement a bandit testing experiment framework, you’ll first need to choose a solution to the multi-armed bandit problem. There are a variety of solutions, and they can appear mathematically daunting.

When deciding the solution to move forward with at Wealthfront, we only considered solutions that seemed reasonable to implement in code:
Epsilon-Greedy
In the epsilon-greedy strategy, the best approach is taken (1 – ϵ) of the time and a random approach is taken ϵ of the time. The ϵ value might be something like 0.2.
Epsilon-First
In the epsilon-first strategy exploration is followed by exploitation. For ϵN trials each of the approaches has a uniform probability of being chosen. After, for (1 – ϵ)N trials the best approach will always be chosen.
Epsilon-Decreasing
The epsilon-decreasing strategy is the same as the epsilon-first strategy, except that the value of ϵ decreases as the trials go on. This allows for significant exploration at the start and significant exploitation once the experiment has progressed.
Thompson Sampling
Thompson sampling attempts to solve one of the limitations of the epsilon approaches, which is that sub-par approaches can perform well due to statistical chance. With Thompson sampling, we read from the “the posterior predictive distributions of each choice using a random uniform variable”. Here’s what the distribution would look like if blue had 4 successes and 1 failure and orange had 1 success and 4 failures:
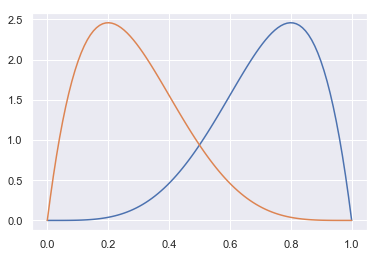
Orange would be chosen ~4% of the time. Thompson sampling is more complex than the epsilon approaches, but it will typically yield slightly better results.
We ended up choosing to move forward with the Thompson sampling approach, because functionally it seemed to be the most reliable, and it would integrate most easily with our existing in-house A/B experiment framework. Additionally, during the investigation we found that Wealthfront actually had built out a Thompson sampling approach in the past, although it had not been in use for many years. We even have an open source version of this Thompson sampling library, and as a part of this project we modernized the code.
Integrating the Solution
After choosing a solution to the multi-armed bandit problem, it is now time to flesh out the architecture. Below is a high-level diagram of how the implementation flows:
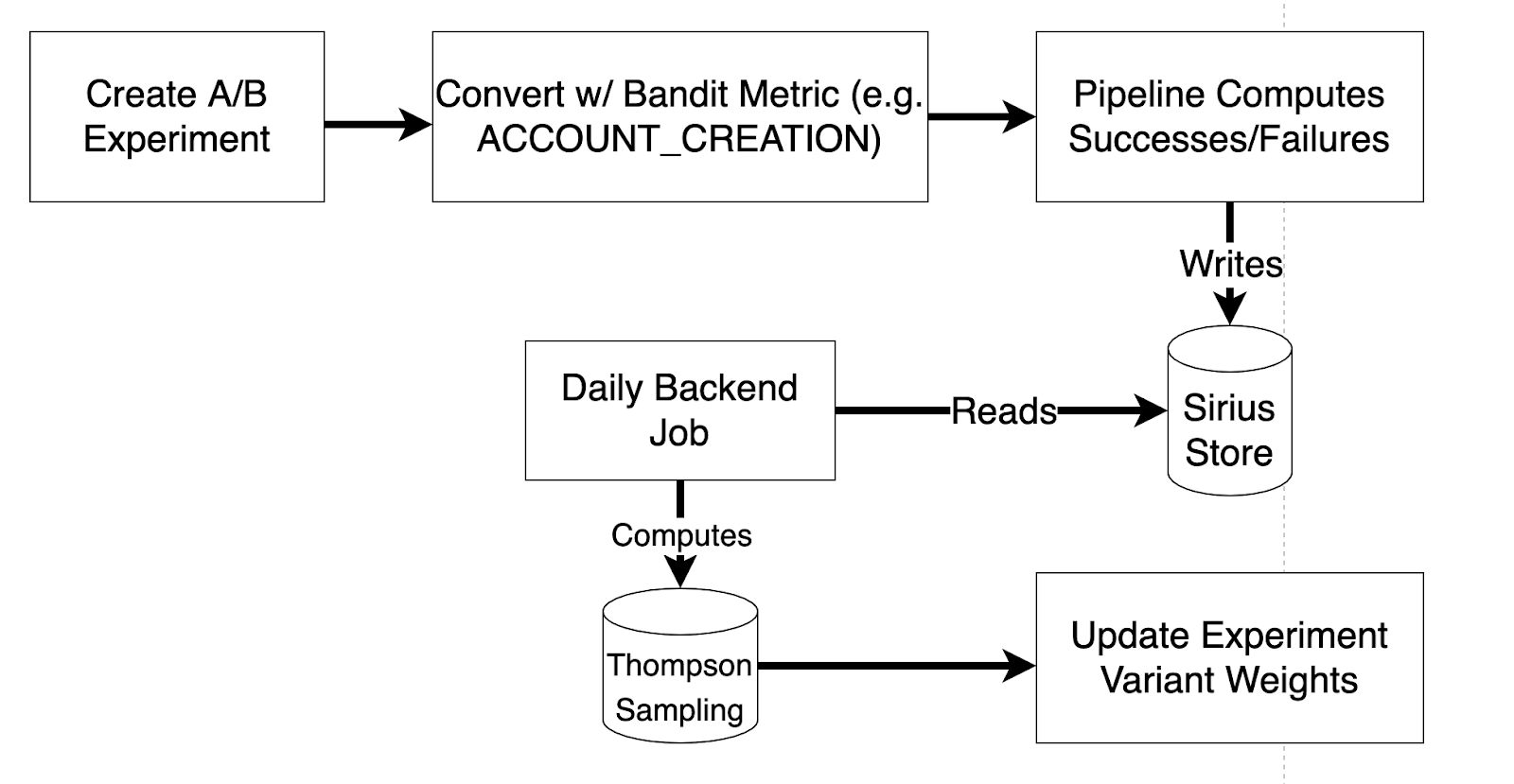
- It’s a direct integration with our existing A/B experiment framework, so you start by creating an A/B experiment as you normally would.
- The next step is to convert it to a bandit experiment, and to do so you need to decide what your “success metric” is. If the goal of the experiment is to increase account signups, then your success metric should be account creation. In the banner experiment example at the start of this post, you could have an event-based success metric where an event would be fired when the user clicks the link in the banner.
- Now that we’ve defined what is a “success”, we need a system to compute the number of successes and failures for the experiment. In Wealthfront’s implementation, we have a spark pipeline that looks at experiment seen events for all bandit experiments. If a user has seen the variant, we use the success criteria to count them as either a success or failure for that variant.
- Once the spark pipeline has computed successes and failures for all variants of bandit experiments, it writes that information out to a store so that we can read it within Wealthfront’s backend services.
- A backend job runs that reads that information and passes it through our Thompson sampling implementation. Thompson sampling uses the success rate of each variant to determine what its weight should be. Each variant weight is then updated accordingly, so that the best performing variants have the largest share of the total weight.
- Repeat steps 4 and 5 daily until we’re finished running the experiment.
Our Initial Bandit Testing Experiment
Earlier this year, we had our first chance to try out our bandit testing framework. We ran an experiment very similar to the hypothetical experiment at the start of the post, where we tested four different banners, shown below.
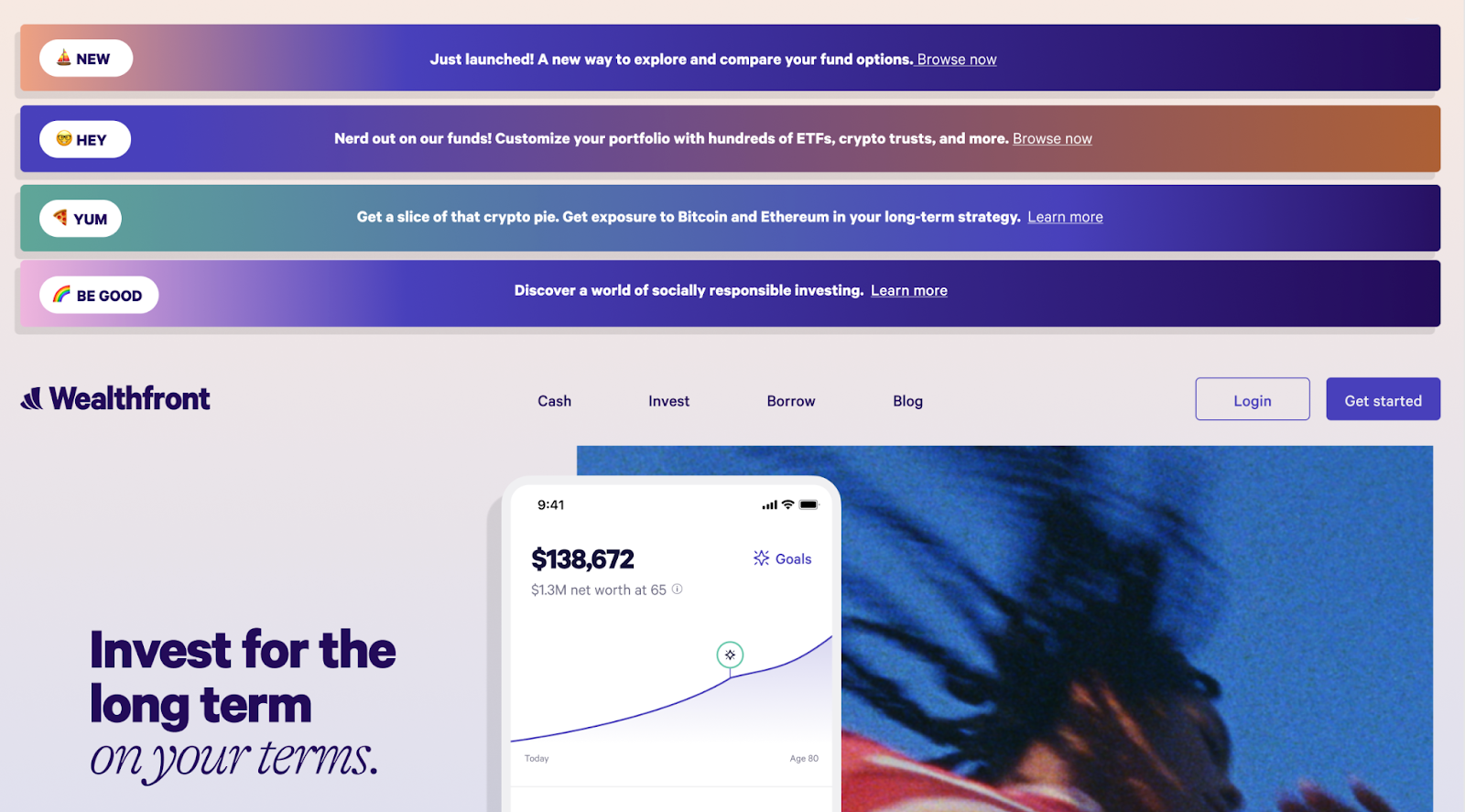
Which banner do you think will perform the best? The results may surprise you.

As shown below, the top banner destroyed the competition with a CTR (click through rate) of 2.6%, compared to the next highest rate of only 1.0%.
| Variant | Impressions | Clicks | CTR |
| A (Explore 1) | 20,896 | 534 | 2.6% |
| B (Explore 2) | 12,115 | 126 | 1.0% |
| C (Crypto) | 12,222 | 124 | 1.0% |
| D (SRI) | 12,220 | 63 | 0.5% |
From the above data you can also see that the top banner garnered the most impressions, because our bandit testing framework quickly gave it the highest variant weight. The results of variant A and B speak to the power of content design, despite advertising the same feature they had drastically different success rates. It’s also interesting that the SRI (socially responsible investing) variant performed so much worse than the others. The leading hypothesis there was actually “feature fatigue”, in that we’d been advertising SRI so much in recent months that it may not have been as compelling to users.
Improving the Framework
There were a few issues we ran into when running the first bandit experiment, and so we came up with some augmentations to the framework:
- Problem: Users could be re-bucketed to a different variant. A user could potentially see multiple variants over the course of the experiment.
- Solution: We prevented users from being re-bucketed, once you’re in a variant you will always be in that variant.
- Problem: Because variant A outperformed by so much, it quickly had 100% of the total variant weight. While this is ideal from an optimization standpoint, it also meant that the other variants were not getting enough impressions.
- Solution: We allocated a floor percentage of 20% that was guaranteed to be distributed across all variants. With four variants in this experiment, this meant that each variant was guaranteed a minimum 5% weight, regardless of how it was performing.
- Problem: The bandit processing would begin immediately after the start of the experiment. It wasn’t an issue for this experiment because it had a lot of traffic, but we wanted to ensure each variant achieved enough initial impressions for reliable Thompson sampling computations in future bandit experiments.
- Solution: We now wait until the experiment has been receiving results for 7 days and that it has received at least 20 success results before running it through Thompson sampling.
Conclusion
Bandit testing can be a great solution for experiments primarily concerned with optimization, or experiments with numerous variants. It can also help progress lower traffic experiments, so that you don’t have to wait months for statistical significance. That being said, A/B testing still remains the primary method for experimentation here at Wealthfront. Nevertheless, bandit testing really opens up the range of possibilities for our experiments moving forward, and we’re very excited to see what we run in the future!
If you are interested in building projects like this with fantastic engineers at Wealthfront, please check out our open positions!
Disclosures
The information contained in this communication is provided for general informational purposes only, and should not be construed as investment or tax advice. Nothing in this communication should be construed as a solicitation or offer, or recommendation, to buy or sell any security. Any links provided to other server sites are offered as a matter of convenience and are not intended to imply that Wealthfront Advisers or its affiliates endorses, sponsors, promotes and/or is affiliated with the owners of or participants in those sites, or endorses any information contained on those sites, unless expressly stated otherwise.
All investing involves risk, including the possible loss of money you invest, and past performance does not guarantee future performance. Please see our Full Disclosure for important details.
Wealthfront offers a free software-based financial advice engine that delivers automated financial planning tools to help users achieve better outcomes. Investment management and advisory services are provided by Wealthfront Advisers LLC, an SEC registered investment adviser, and brokerage related products are provided by Wealthfront Brokerage LLC, a member of FINRA/SIPC.
Wealthfront, Wealthfront Advisers and Wealthfront Brokerage are wholly owned subsidiaries of Wealthfront Corporation.
© 2022 Wealthfront Corporation. All rights reserved.