From both a company and engineering standpoint, Wealthfront values making decisions backed by quantitative methods. As noted in our previous blog post, Statistics is Eating the World, the key to enabling decisions backed by data is to build a platform that is automated and can scale across all aspects of our business. One of the most valuable characteristics of our data platform is integration with third party systems to include external data into our models and dashboards. In this post I’ll go over why integration with third parties is valuable, and outline 3 strategies we use to get data from third parties. I’ll also cover common considerations that we make to ensure our data pipeline runs reliably.
Tracking Data Internally vs. Externally
Often times, analysis can be done exclusively with data from our internal systems. For example, if Wealthfront was interested in what information our clients want to see for their account, we could monitor web usage and page views to start forming conclusions about visitor intent. There are other cases, however, where the data we need lies outside of our internal systems. For example, if we needed to gather information about a certain traded security’s prices, we would need to obtain that data externally from an exchange or data vendor. Here are some general uses for importing data from external sources:
- We import data from systems that directly interact with our major systems to confirm functional competence
- We import data from vendors that don’t interact with our systems, but impact our business metrics
- We import data from providers that will enable additional analysis and data quality
Extract, Transform, Load
For these cases it is necessary that we create an automated pipeline that can access data from the third party source and transform it into a format that can be stored into our data platform to be used in models and dashboards. This process is commonly known in industry as Extract, Transform, Load, or ETL. Third party systems come in all shapes and sizes, so no one strategy will suffice to extract data from everyone. The 3 ways we commonly ETL data are as follows:
- Making calls to a Third-Party REST or SOAP API
- Web scraping
- Secure File Transfer Protocol (SFTP)
REST and SOAP APIs
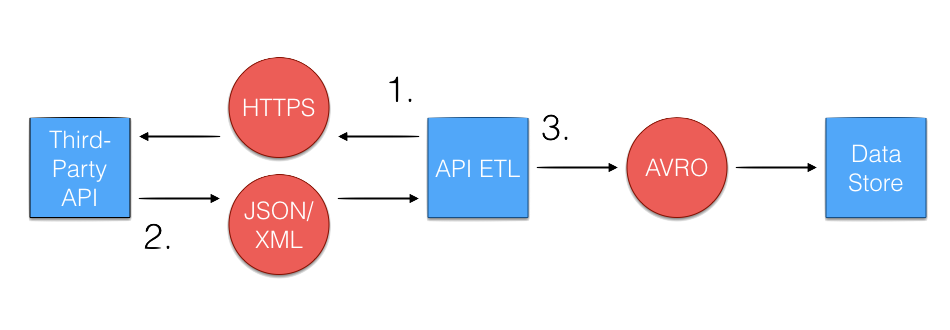
Often times, a vendor will provide an Application Program Interface, or API, for its users to obtain key metrics for the service it’s providing. When extracting data through an API, the ETL code will make an HTTP request to a given API endpoint for the desired metrics. Depending on the individual system, the API will return a response in a standardized format such as JSON, CSV, or XML. The ETL parses and converts the data to a normalized format (Avro format in Wealthfront’s case) and writes the data to the data storage. Here is an example ETL that is obtaining trading prices for Google, Apple, and Facebook Stock from a fictional API:
public class StockPricesETL {
private static final String API_URL = “https://api.stockprices.com”;
private static final String STOCK_PRICES_ENDPOINT = “/prices/%s”;
private static final String ACCESS_TOKEN = “?access_token=someAccessToken”;
private static final String DATE_PARAM = “&date=%s”;
private static final List<String> STOCKS = ImmutableList.of(“GOOG”, “FB”, “AAPL”);
private static final long SLEEP_TIME = 2000;
public List<StockPriceAvro> getStockPrices(LocalDate date) {
final ObjectMapper mapper = new ObjectMapper();
final List<StockPriceAvro> stockAvros = new ArrayList<>();
for (String stock : STOCKS) {
final String responseJSON json = HttpsConnection.sendGet(formatEndpoint(date, stock));
final PriceList parsedStocks = mapper.readValue(responseJSON, PriceList.class);
stockAvros.addAll(convertToAvros(parsedStocks));
sleep(SLEEP_TIME);
}
return stockAvros;
}
private String formatEndpoint(LocalDate date, String stock) {
return String.format(“%s%s%s%s”, API_URL,
String.format(STOCK_PRICES_ENDPOINT, stock),
ACCESS_TOKEN,
String.format(DATE_PARAM, date);
}
}
In addition to making the call to the correct endpoint api.stockprices.com, it is necessary to include the proper authorization for the API call ?access_token=someAccessToken. In this example, an access token was included within the URL of the request as a query parameter. Depending on the API, the authorization may need to be sent through a different method, such as through header of the HTTP request, or in the body of a request (common for SOAP APIs). When using APIs you may also need to be mindful of the frequency of requests made, as many institute a rate limit for API requests.
Web Scraping
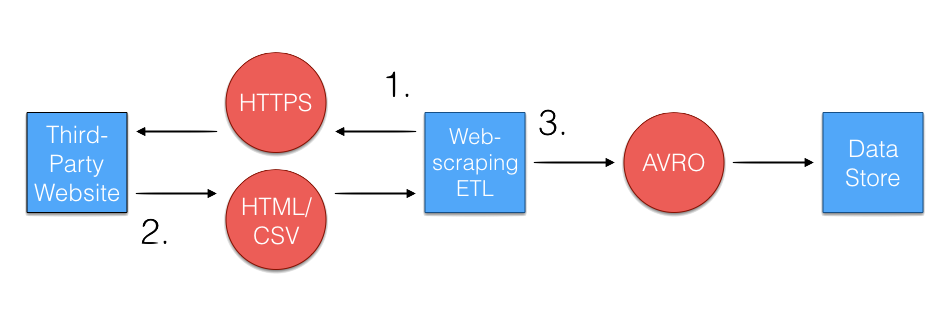
Not all vendors provide an API to extract data from, and in these cases it will be necessary to web-scrape the web user interface and dashboard that users log-into via browsers to obtain the data. When codifying this into an ETL, the ETL looks similar to the ETL for APIs. HTTP requests are made to the web server intended for internet browsers, and once proper authorization is provided, the ETL can access a URL that has the relevant data. The data will often be in a normalized format like a CSV, which needs to be parsed and converted into the appropriate format for data storage.
The process for implementing a web scraping strategy can often be a frustrating process compared to ETLs that directly request from an API. Many websites are not built with the intention of being browsed by a script, requiring the engineer to have to creatively devise a strategy for finding the right sequence of HTTP requests and HTML cues to get to the right data. Additionally, there is no guarantee from the vendor that the website will stay the same, potentially causing a scheduled ETL to fail without forewarning. For these ETLs, we build monitoring to detect and alert when an ETL has failed due to potential updates made to the web server.
Secure File Transfer Protocol (SFTP)
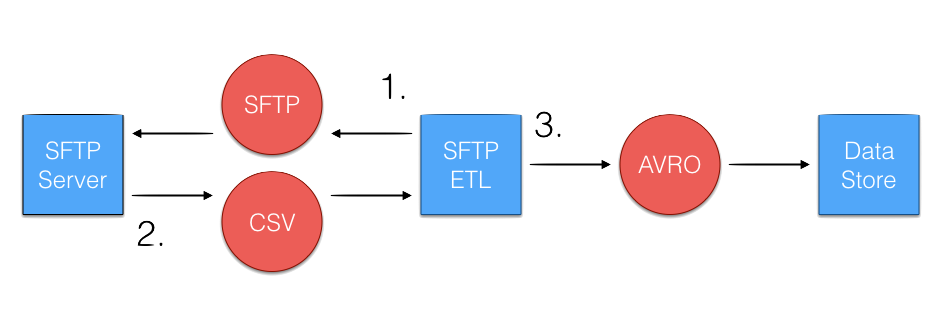
There are some vendors that have neither an API nor web dashboard, or simply prefer transferring data across SFTP. Typically, an agreement is made between the two parties on what the file directory and name, as well as the normalized format, such as CSV. The ETL for this strategy consists of making an FTP Get request for the desired data to read in the file. The file ideally should be in a standardized format, which can be parsed to convert into a type that can be written into data storage.
The implementation of the ETL using SFTP is fairly straightforward, but there is some added overhead in the maintenance of the SFTP server itself. The access for users performing Put and Get requests needs to be established such that no user can read/change data beyond what is appropriate. In addition file sizes should be monitored to make sure disk space doesn’t fill up, and that ETL data are backed up in a separate location should the SFTP server fail at any time.
Qualities of Reliable Third-Party ETLs
An important consideration of third-party ETLs is that they are communicating with a system that we have no control over. Situations can and will occur when your scheduled ETL fails because it attempts to access a system that is down or has been modified. Here are a few examples of instrumentation that has helped us maintain reliable ETLs:
- Exception handling: we make sure that the system properly publishes exceptions if a request makes a bad request, or if the ETL cannot properly convert a response into the normalized format (e.g. because of a missing or null value).
- Retrying requests: given inconsistencies in network connections, request queueing and other factors, it’s possible that a request sent does not get the proper response, but the third party service is running fine. In these cases, implementing a standard retry functionality will make sure that ETLs will succeed through these issues.
- Data quality checks: sometimes the third party will return a successful response, but will return no data or incorrect data. Having checks on the output or in downstream data quality checks for recent data can help catch these incidents.
- Well-structured and maintainable code: it’s common during the lifetime of a third-party ETL that it will have to be updated, either because of a version update in the API, or because of a change in web UI for a web-scraping ETL. Keeping the code readable and maintainable will minimize the time needed to update them.
- Real-time monitoring and reporting: as is true for any live system, it is necessary to create instrumentation that will check the status of scheduled ETLs. At the minimum, monitoring should check that ETLs run on schedule and execute successfully. Should the ETL fail for any reason, the system will notify on-call engineers that a production level failure has occurred.