Twenty years ago, one would have hardly heard the phrase “A/B testing”. In 2000, Google served its first A/B test to determine the optimal number of search results to display. In 2011 alone, they ran 7000 A/B tests across their platforms. A/B testing has become the bread and butter of product decision-making for Silicon Valley giants and startups alike.
As a data-driven company, Wealthfront depends on A/B tests to take the guesswork out of product decisions. A/B tests empower our team to roll out new features to our clients in a systematic and low-risk manner. We take every opportunity to learn about our clients’ behavior through tests, so at any given time, we may have dozens of A/B tests running in our desktop app.
What about A/B testing on mobile?
While our desktop site is a happy A/B testing wonderland, we hadn’t brought our A/B testing capabilities to our iOS app or Android app. Previously, we had used product insights from our web A/B test results to drive product decisions on our mobile apps. This makes a tenuous assumption that if a new design or feature performs well on desktop, it should also perform well on mobile. This isn’t always true. Wealthfront clients engage with the iOS app much more frequently but deposit money less frequently than clients on desktop, among other differences. In the past, we haven’t had a way of identifying what works optimally for this distinct mobile cohort.
Until now. Over the past few months, we’ve iterated on a few designs for an efficient and lean A/B testing infrastructure for our mobile clients.
Mobile A/B testing is deceptively non-straightforward. One of our sources of inspiration is Airlock, Facebook’s mobile A/B testing framework built during their transition from a custom web stack to a native mobile stack. As Airlock designers experienced, a native mobile A/B testing infrastructure introduced many edge cases that arose through difficult trial and error. Throughout our own process, we’ve tried to leverage the lessons they learned by building Airlock, and will discuss the four areas of focus below.
Backend infrastructure
A/B testing schema
The first step of building out the mobile A/B testing infrastructure was the backend A/B test schema. Our initial schema broke up A/B tests into three separate tables depending on whether they were “active”, “served”, or “resolved.” Any created experiments start out as “active” experiments. “Served” experiments contain data about bucketing and subject assignments while “resolved” experiments encapsulate the winning variant. Variant metadata was kept in a separate table and referenced by individual experiments.
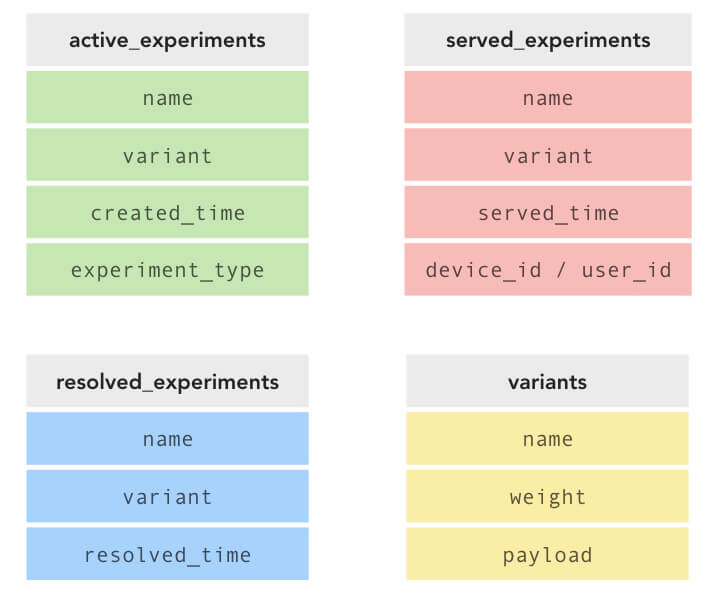
This v1 schema supports virtually any combination of experiments and allows for fine control. It also allows scaling A/B testing almost indefinitely – having key experiment data duplicated across three tables would’ve allowed for faster read times, which optimizes for table reads (serving existing variant assignments to users) over less frequent writes (new bucketing assignments or experiment creation). The flipside is the implementation and integration complexity. Our anticipated scale of A/B tests and subjects did not require this level of denormalization. So we have decided to look for simpler alternatives, ones that would allow us to iterate with design and implementation quickly.

For v2, we considered a single experiment table. We would not explicitly store a record for each experiment subject, but constantly recompute a subject’s bucketing for any new experiment by taking the user’s ID modulo N, where N is the number of variants for this particular experiment. We would store variant metadata as a JSON string within the experiments table as a way to further reduce the need for additional tables.
This bucketing algorithm, however, only supports variants with equal weights (e.g. two variants weighted 0.5 or three variants weighted 0.333). With the same minimalistic schema design, we can extend the bucketing algorithm to support variable variant weights, and by extension, feature ramping. First, we break up the range of numbers from 1-M into N segments, where M is the inverse of the weight precision (if the precision were 0.01, then M is 100). By defining N segments with desirable proportions, the bucketing algorithm will weight variants differently. For instance, let M be 100 with three variants A, B, C and desired weights 10%, 20%, and 70% respectively. We would define segments 1-10, 11-30, and 31-100 as variants A, B, and C respectively. Determining the variant assignment for a new user is now as simple as computing user ID modulo M and choosing the variant corresponding to that segment. By updating the variant weight in the JSON metadata, the v2 design gracefully supports variable variant weights and dynamic variant ramping.
At this point, we realized that the ability to whitelist subjects (manually bucketing a user into variant A or variant B) would be useful for employees or corporate partners who require a particular experience. So we simply added an explicit subjects table that would record bucketing assignments. This second table adds no complexity to the bucketing logic, but allows us to overwrite the default bucketing user ID modulo M algorithm if need be.
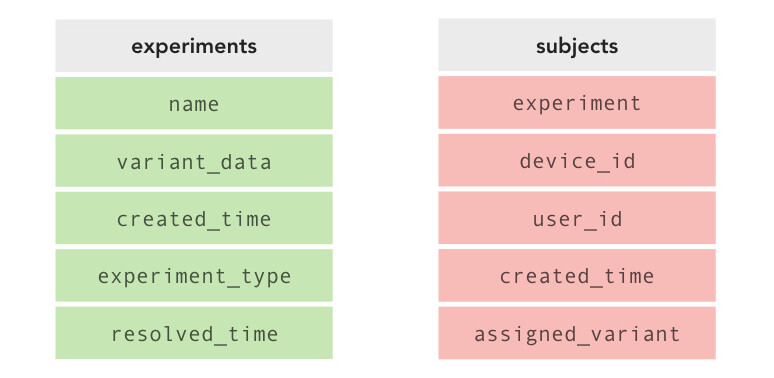
This design is simple, requiring only two tables to store information about experiments, subjects with variant assignments, and all relevant variant data. Moreover, this design scales well enough to the number of experiments and subjects we expect at any time. Feature ramping would involve reassigning a portion of already-bucketed subjects, so an additional whitelisted boolean column in the subjects table would enable feature ramping while simultaneously preserving any previously whitelisted assignments. Thus, this v3 schema can support our use cases and also work seamlessly with iOS, Android, and potentially desktop web A/B tests as well.
Experiment types
Another interesting consideration is that there are two types of A/B tests: user-level and device-level.
User-level A/B tests, which constitute the majority of our A/B tests, are only displayed within the logged-in experience of the mobile app and need to be consistent for each distinct user per experiment. An example of a user-level experiment might be showing a different design on the Wealthfront account view tab with new functionality to add funds directly from that view. If a user assigned to this variant were to log in on multiple devices, they should see a consistent experience across all their devices, because this experiment is tied to their account.
Device-level A/B tests need to be consistent for each distinct device, independent of the user who is using the device. For example, if we wished to try out a new app-wide color scheme, we would want the color scheme to be consistent whether the user were logged into the app or not. Every user using that device would need to see the same color scheme on that device.
Thus, we need to store the A/B test type in the experiments table so that 1) we only consider bucketing for user-level A/B tests if the user is logged in and 2) we know whether to return an existing assignment or a new bucketing assignment.
API design
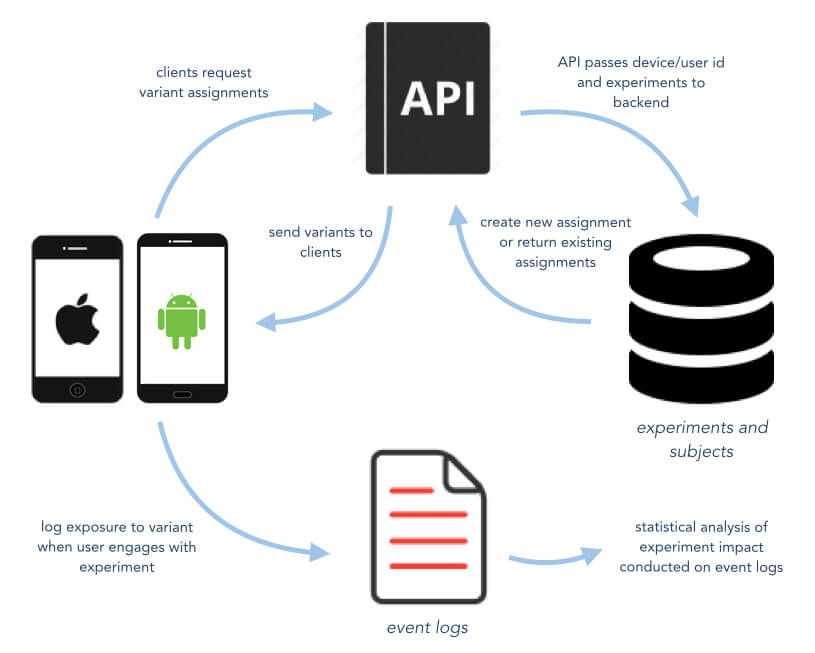
A good API allows developers to offload complicated and reusable logic from clients to the server. Management of all subjects, records of which bucket they were placed in, and what variant they should see at any time should be coordinated by the server with the API acting merely as a messenger from server to client apps.
Resolved boolean
As discussed later, mobile A/B testing faces a unique challenge that web A/B testing does not: backwards compatibility and handling of outdated client app versions. With desktop web apps, new releases are immediately seen by desktop users; a nice side effect of this is that experiment resolution propagates to users immediately following web app deployment. On mobile, conversely, there will always be a contingency of outdated app versions, which means that some percentage of user devices will request resolved A/B tests that should be eliminated from the most up-to-date version of client code.
We felt strongly that the API response not include any information about whether an experiment has been resolved or any other metadata. Each client – either up-to-date or outdated – has a list of expected experiments for which the API should provide variants. Clients, therefore, should naively rely on the API to return the correct variant for this user/device in all cases.
JSON payload
Another design consideration that arose was the addition of a JSON payload in the API response. One prospective use case for such a payload is for the server to send more complicated data through the API that would be used directly by the client in implementing the experiment. For instance, if we wanted to experiment with a red vs blue colored submit button, we could send an array of [255, 0, 0] or [0, 0, 255], respectively, which the client would use directly in code. The additional capability offered here is that we could run experiments with a huge space of possible variants in quick succession without having to redeploy a new version of the client code. Suppose we wanted to try 50 shades of green for our mobile app transfer button. We would be able to redefine variant A and variant B to be different shades of green dynamically over time and iterate quickly through all 50 possibilities. However, this use case is relatively narrow, as most significant mobile features that we would A/B test (e.g. different signup flows, new modals and views) necessitate significant changes to the client code and cannot be implemented via the content of a JSON payload.
Moreover, as discussed later, each experiment needs customized event logging on the client side. Changing the definition of variant A from “dark green” to “light green” in the middle of a single experiment’s lifecycle would require that experiment analysis cross reference event logs with backend database records to attribute each user ID to the correct phase of variant A. Needless to say, redefining variant A for a single experiment would significantly complicate the analysis, in addition to being a limited use case.
A more sinister consequence of the payload is the treatment of this JSON payload as a quick-and-dirty API endpoint. Good API design advocates that data be received by the client from the API via a well-formed API response and not an untested, potentially ill-formed JSON payload from the A/B test endpoint. If the client needs data from the server for an A/B test, then this data should be codified into a valid API endpoint, which then can be used in production if resolved. The alternative is to dump this data into the payload for the A/B test lifespan and then rebuild the correct API endpoint that returns this same data after experiment resolution. In any case, the API endpoint should be used rather than relying on a payload. It is easy to imagine that the convenience of client apps consuming data through the A/B test payload could prove tempting enough to result in a future dystopian client-API relationship where all experimented features are communicated through a quick-and-dirty payload rather than properly refactored out into the correct endpoint.
Mobile client
Outdated clients
One of the distinct challenges with mobile experiments is supporting outdated mobile clients. Each mobile client version has its own set of the expected N experiments that it will encode in client-side code. This set of N experiments is then sent to the API, which will return the correct variant for each experiment. If a user doesn’t update their mobile client often, some of those N experiments will have been resolved. We cannot, therefore, remove resolved experiments from consideration or blow them away from the experiments table. Our experiments table needs to keep track of the winning variant for each resolved experiment so that we can return this resolved experiment to outdated clients.
On the client side, we hardcode the paths for all variants using a simple if/else block in client code. Clients trust the API to return the correct variant at all times, even as an outdated client requests a resolved experiment. If an experiment is resolved, all clients will receive the winning variant.

Multiple experiment types
In order to support multiple experiment types, the mobile apps query the API once upon app launch (to fetch assigned variants for device-type experiments) and once after user login (to fetch user-type experiments). This mechanism ensures that we can provide a consistent user experience while still testing different types of experiments.
Performance considerations
It’s no secret that fast mobile app launch time is critical for a good user experience. It is absolutely imperative when designing a mobile A/B testing infrastructure that the API calls we make do not create additional startup latency. After all, A/B tests are not critical to user experience and should not slow down access to primary features. Since we are making an API call upon app launch to fetch all device-type experiments, we needed a way to assign the correct variant for this user/device without blocking the UI from rendering responsively.
We opted to fetch all experiments in the background and when the response is completed, store the results locally on the mobile device. If the experiment has rendered before the API results returned and stored locally, the user will see the default “control” variant for the very first engagement with the experiment. Thereafter, the client app will have cached the result of the correct variant and will display this to the user appropriately. With lazy loading of A/B tests from the API, the user will see the correct variant without compromising quick startup time.
For example, suppose we were running a user-type (i.e. logged-in) A/B test to decide whether showing a “Cash and Investments Projection” banner notification would favorably increase user engagement. A user bucketed into control would not see the banner under any circumstances. A user bucketed into the variant “show notification” bucket may see the control experience the very first time, and would then see the banner notification from the second viewing onwards.
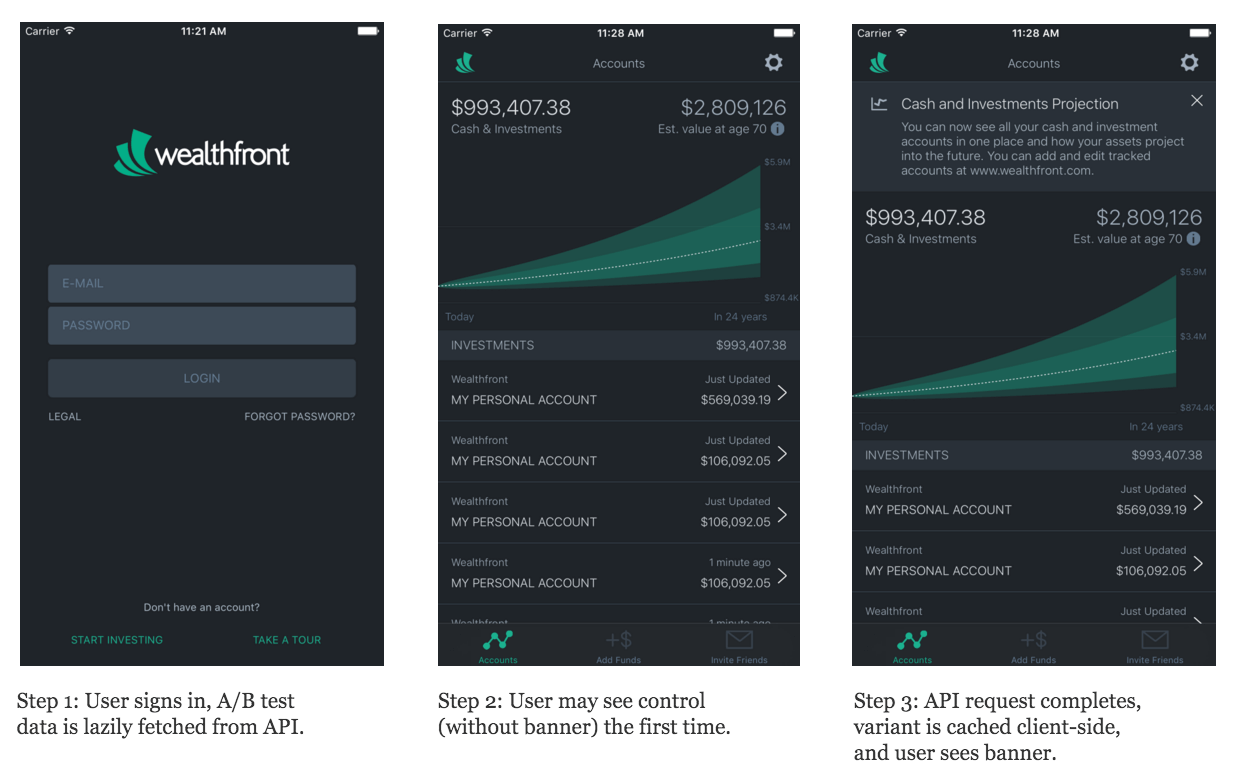
Finally, in order to ensure a robust client experience, our mobile client apps define default control behavior to render in the event of a network outage or a malformed API response, such that the UI always looks good and falls back to control if needed.
It turns out that this one-off exposure to the control is relatively uncommon, only occurring if the API request cannot finish before the user reaches the view containing the experiment. This might happen for experiments on the first page after app launch (e.g. the login or home page) or for users with a poor network connection. It might seem that, having seen multiple variants, these users are biased and should be excluded from analysis. However, provided that the control is defined to be the same experience as in the previous release, as opposed to an altogether new feature, then the observance of control the first time is merely delaying introduction of the variant experience by one app launch. We should not need to ignore these data points in analysis.
Experiment analysis
A key lesson Facebook’s mobile team learned in building Airlock was the importance of running analyses on events logged by the client and not on the backend database records for experiment subject bucketing. Unlike web A/B testing infrastructure, backend database records of bucketing events couple loosely with clients actually experiencing the experiment on the front-end. Consider a mobile user who opens the app, gets bucketed by the server into variant A, but immediately closes the app before visiting the tab that has the experiment. She doesn’t open the app again for days. Clearly, we cannot trust the backend database saying a particular user saw variant A; only the client event logging can determine this. It would be a costly mistake to use the backend database records to count exposure to experiment variants for analysis.
Experiment exposure logging on the client side is critical. If an experiment is rendered at the very top of an iOS view controller, the iOS method [self viewDidLoad] might be a sufficient place to log exposure. However, if the experiment is rendered on a distinct view component at the very bottom of the same view controller, then logging exposure should wait until the user has scrolled down and the view in the question is actually manifest to the user. So, the logging for each experiment has to be coded with that particular experiment to ensure correctness.
Mobile A/B testing presents many edge cases and constraints that are not present for desktop web A/B testing. We recently shipped our first A/B test to iOS users (Android to follow shortly) and look forward to the capabilities A/B testing gives us for rapidly improving the Wealthfront experience for our mobile clients. This accomplishment was an incredible group effort that started with our interns last summer, and so a big thanks goes to Clay Jones and Norman Yu, who spearheaded the first iteration. Additional thanks to Adam Cataldo, Nick Gillett, Pete Rusev, Tao Qian, Fabien Devos, Luke Hansen, and the Wealthfront iOS team: John Lee, Kevin Choi, Daniel Zheng, and Steve Flory.
To learn more about A/B testing at Wealthfront, check out our previous blog posts written about using shrinkage to avoid A/B testing errors and Bayesian Inference.
Like what you see? Join us and let’s build more great things together!