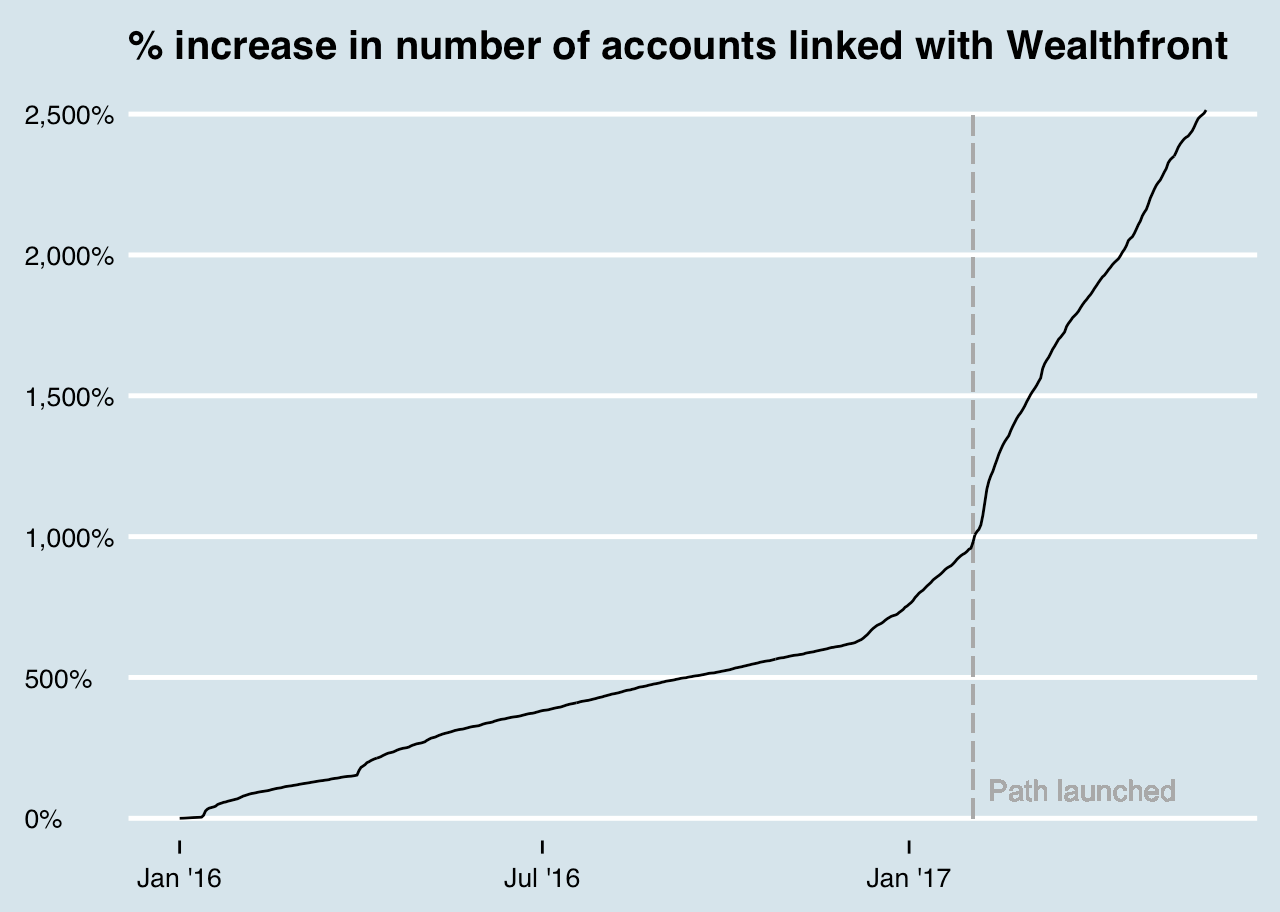
Wealthfront is growing fast, and the quantity of data we collect is growing faster. With the launch of Path, we’ve seen a large increase in the number of non-Wealthfront accounts our customers have linked over time (see below). We have plans to increase the breadth of automated financial advice we provide for our clients, so we’re expecting to see the number of linked accounts accelerate. On top of this, we have an ever-growing set of financial services we offer, giving more people a reason to use Wealthfront. This has forced us to think hard about how we scale.
Against this backdrop, Wealthfront was built off MySQL. It has served us well, and continues to do so. For any new website, it’s hard to go wrong with MySQL and a good ORM. We still use MySQL, and we still use Hibernate, but we’re increasingly moving beyond this pattern. There’s nothing inherently wrong with MySQL, but as our business logic complexity increases, we’ve had to add new data access patterns in order to scale.
The problems with the MySQL pattern
Like all companies with a website, we tend to add new services over time. These new services get linked with new databases. As good users of MySQL, we are careful not to store redundant data in our databases. This normalized pattern is great in that it eliminates a class of errors associated with conflicting versions of truth, but it comes with a cost. Let’s say we need to fetch data for some of the financial advice we offer in Path. We would likely need to fetch data about the user’s accounts at Wealthfront from one database, data about their non-Wealthfront accounts from another, and data about historical prices from yet another. Our performance is limited by the slowest database fetch, and the fetching is often hard to parallelize due to data from one fetch determining what the next fetch should be.
This same example comes with another problem. Once we collect all of the data, we need to do some non-trivial computations, like classify checking account transactions to estimate a client’s savings rate and estimate the rate of return for a client’s non-Wealthfront accounts. If we store these computations in the database, we’re violating normalization. If we don’t store them somewhere, we’re slowing down the time it takes to serve financial advice to the client, while adding non-trivial load to our backend services.
In a perfect world, we would identify these types of scalability issues before they pop up, but in practice we’ve often found them when clients are experiencing slow load times or we’re having availability issues with one of our services. When we dig in, we often find long cross-system call graphs, when the fetch time is the bottleneck, or slow call processing time, when compute time is the bottleneck. We’ve built internal tools to help us find and debug these issues, but more importantly, we’ve changed the patterns for how we access and serve data.
New access patterns
The first key insight we had was that we needed a way to store precomputed data. We jumped on the NoSQL train, and ended up with a thin wrapper around cdb as our key-value store. We had originally used Voldemort for this, but found that it didn’t suit our needs as we transitioned to a multi-colo environment.
We also started precomputing things. We initially built batch Hadoop jobs, which later evolved into batch Spark jobs. The move to Spark helped with performance for machine learning workloads, but to be fair to Hadoop, Crunch served us quite well for some time. Many things only need to be computed once a day, like the daily returns we show our clients. For these types of workloads, computing them in batches on Spark and then storing them in our key-value store is a perfect fit.
In other cases, waiting for a daily or hourly job to finish is unacceptable. For instance, when clients link a new account, we want to be able to incorporate that into their Path recommendations as soon as possible, without putting too much load on our systems. To balance speed and load, we use Spark Streaming, which allows us to update precomputed data incrementally at relatively low latency with high bandwidth. We settled on the lambda architecture, precomputing as much as we can in batches and updating the results from streaming as new data becomes available. There’s a tradeoff with using streaming, which is that it reduces the latency for us to respond to a client’s request, since data is precomputed, but it delays freshness by a few seconds while the data runs through the streaming platform. This adds UI complexity to keep the experience delightful.
Where we are today
This transition beyond MySQL is not complete. There are some parts of our system we are still moving off MySQL, and there are others for which MySQL will likely continue to make more sense than any other pattern. For honest transactions, like trades or cash in and out of an account, a transactional database makes sense as the system of record. It’s critical that we have only one source of truth for the value in a client’s account. The important thing for us is that we now have access to these other patterns, so scaling beyond MySQL is straightforward when needed.
Disclosure
Nothing in this blog should be construed as tax advice, a solicitation or offer, or recommendation, to buy or sell any security. Financial advisory services are only provided to investors who become Wealthfront Inc. clients pursuant to a written agreement, which investors are urged to read carefully, that is available at www.wealthfront.com. All securities involve risk and may result in some loss. Wealthfront Inc.’s financial planning services are designed to aid our clients in preparing for their financial futures and allows them to personalize their assumptions for their portfolios. Wealthfront Inc.’s free financial planning guidance is not based on or meant to replace a comprehensive evaluation of a Client’s entire financial plan considering all the Client’s circumstances. For more information please visit www.wealthfront.com or see our Full Disclosure. While the data Wealthfront uses from third parties is believed to be reliable, Wealthfront does not guarantee the accuracy of the information.