In Part 1 of this series, we gave a brief look into the data platform at Wealthfront, focusing on how we minimize data processing downtime while redeploying our Spark Streaming jobs. In this final part of this series, we will describe how we coordinate the data in our serving layer and wrap the blog post up by showing how all the pieces fit together to make redeployments invisible to our customers.
Coordinating the Serving Layer
Our serving layer consists of a home-grown key-value store which we call Sirius that was written around cdb and rocksdb. As a result of Lambda architecture, this key-value store treats real-time incremental writes differently than batch writes. Data from each computation layer (batch and real-time) are stored in separate layers (batch and incremental, respectively) within the database. The batch layer is treated as the final source of truth, while the incremental layer is used to provide the most up-to-date view of data. For each query, the database will first search for the key in the incremental layer before attempting the batch layer.
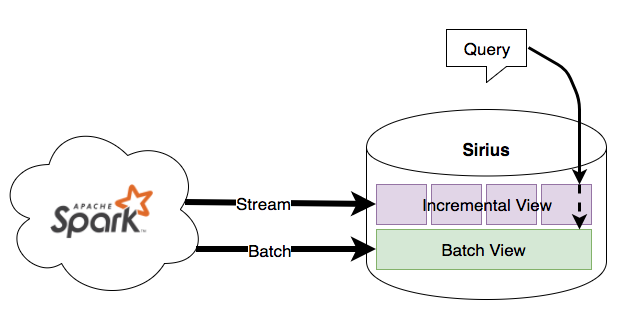
This structure makes a good foundation to coordinate between versions of data from different streaming job instances. In order to achieve this, Sirius stores different versions (mapped from unique job ID) of incremental data in separate silos and only applies updates from the respective job version into each silo.
When Sirius receives the notification that a job instance has caught up, it will serve queries off data from that version and delete the previous version data.
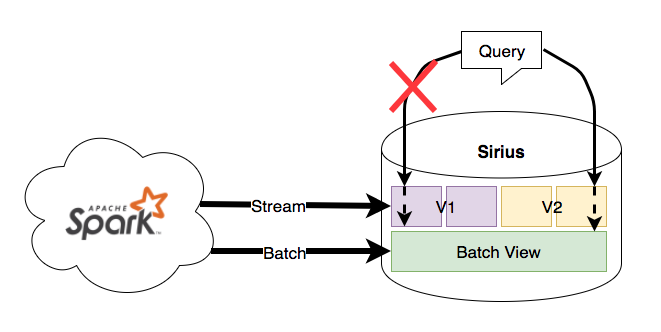
You can see that Sirius is keeping track what data to serve using essentially a pointer. This pointer makes it possible for the reprocessing job to retransform data in isolation as it catches up while the original job continues to power the exposed view. Note that the batch view is shared across incremental versions since it continues to serve as the final source of truth of historical data regardless of incremental version. Swapping the batch view is an atomic operation so updating batch data is more trivial than the incremental layer.
Putting It All Together
So putting it all together, our Spark Streaming deployment system looks like this:
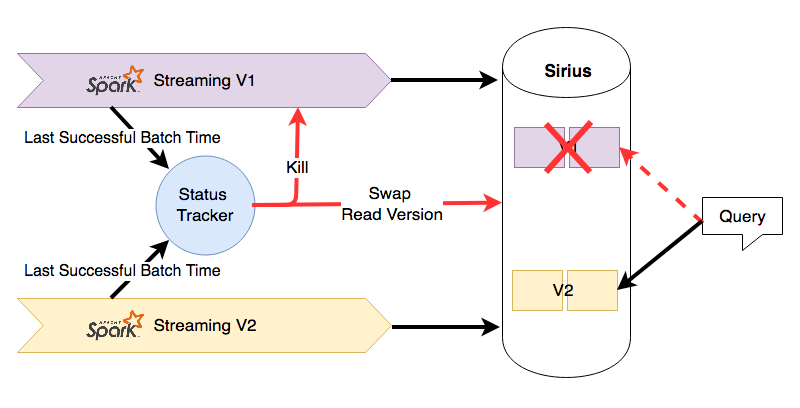
- A new Spark Streaming (V2) job is launched, running new code and writing into a separate silo in Sirius.
- As the Spark Streaming job progresses, it sends messages containing the pipeline name, version ID, and latest micro-batch BatchTime to the StatusTracker.
- When the StatusTracker has observed that the new Spark Streaming job (V2) is caught up to the original job (V1), it shuts down the original job and sends a notification to Sirius to swap the read version.
- Sirius receives the swap notification, and begins to serve queries off the data generated by the V2 Spark Streaming job. It also deletes the data from V1 to save disk space.
The end result of this deployment system is now when we deploy new code into our Spark Streaming pipeline, there is no perceivable downtime for our users in which data is not being updated. The job running an older version of code provides fresh data while the new job catches up. Once the new job is ready to take over, the serving layer seamlessly switches over to serving data from the new job.
Future Work
While this Spark Streaming deployment system has been in production for months now, there are still lots of features we’re hoping to add in the future. Namely:
- Persistent storage of job state for historical analysis of job performance.
- A central deployment manager that can provide an easy interface to manage and track streaming pipelines
If building this sort of data processing infrastructure to revolutionize financial access sounds interesting to you come join our team!
Wealthfront prepared this blog for educational purposes and not as an offer, recommendation, or solicitation to buy or sell any security. Wealthfront and its affiliates may rely on information from various sources we believe to be reliable (including clients and other third parties), but cannot guarantee its accuracy or completeness. See our Full Disclosure for more important information.
Wealthfront and its affiliates do not provide tax advice and investors are encouraged to consult with their personal tax advisor. Financial advisory and planning services are only provided to investors who become clients by way of a written agreement. All investing involves risk, including the possible loss of money you invest. Past performance does not guarantee future performance.