Recently, Wealthfront CEO Andy Rachleff shared the following vision at the CB Insights Future of Fintech conference:
“Our vision is to deliver a service where you direct deposit your paycheck with us. We automatically pay your bills. We automatically top off your emergency fund, and then route money to whatever account is the most ideal for your particular goals, whether they’re at Wealthfront or elsewhere.”
Soon after, some aptly described this as “self-driving money™.”
Here’s some good news: we are closer to this future than you might think. When we made Path smarter back in December, we introduced the first version of our new savings advice algorithm. In this release, Path was able to provide advice on which investment accounts to put money in and catch common mistakes like not topping off your 401(k) or IRA account. In the process of adding home planning, we realized we had a significant gap here of focusing solely on longer term goals like retirement and neglecting short-term ones. With the introduction of our home goal, we needed to overhaul our algorithm to not only account for which accounts to save in but also which goals to save towards. Long story short, our exceptional team of PhD researchers devised this two-dimensional algorithm, and our talented engineers put it into place. What does this mean for our future vision? If you’ll excuse the car pun, it means we already have the GPS to route money to whatever destination is the most ideal for your particular goals:
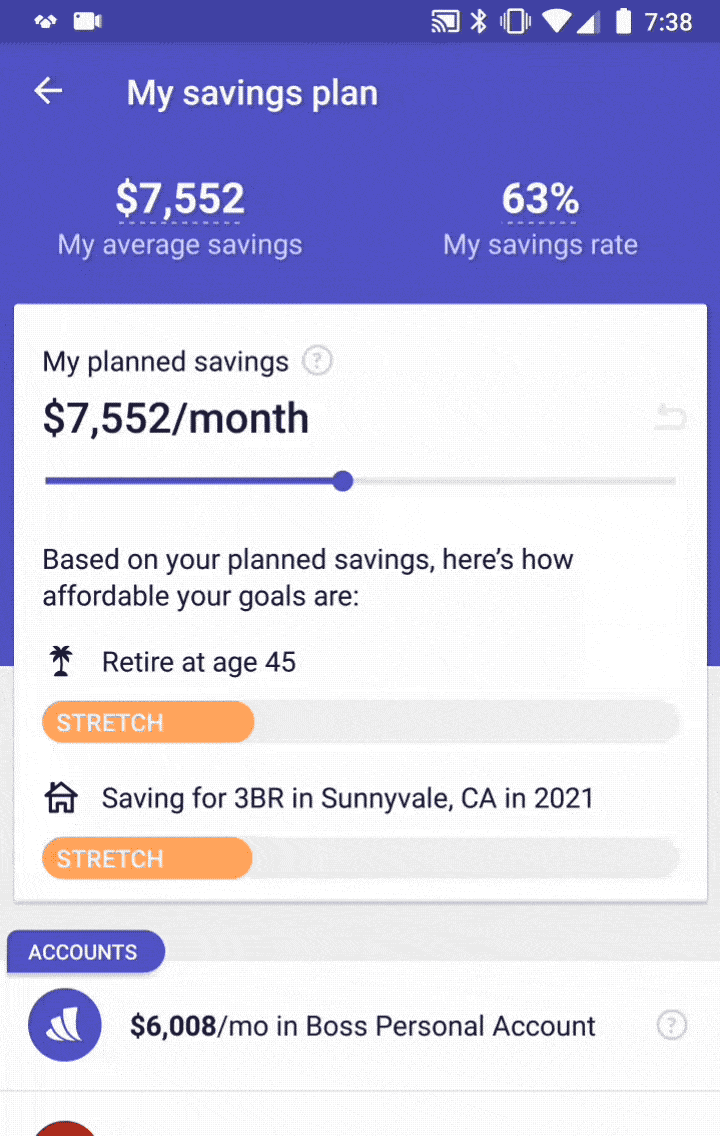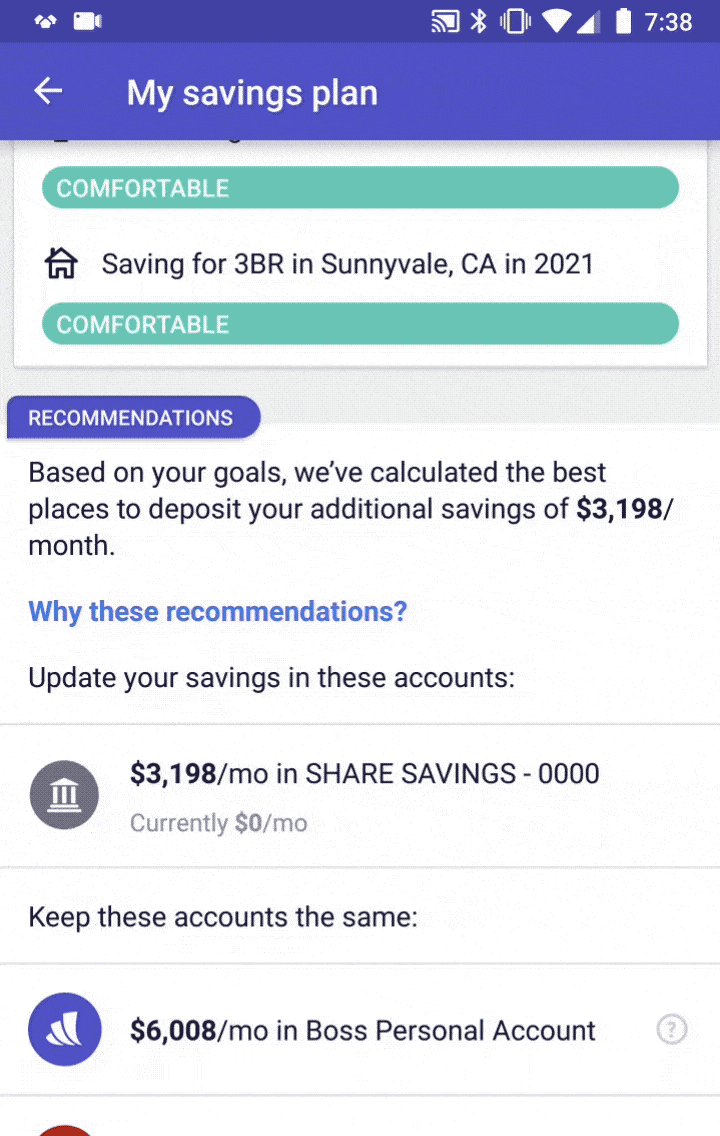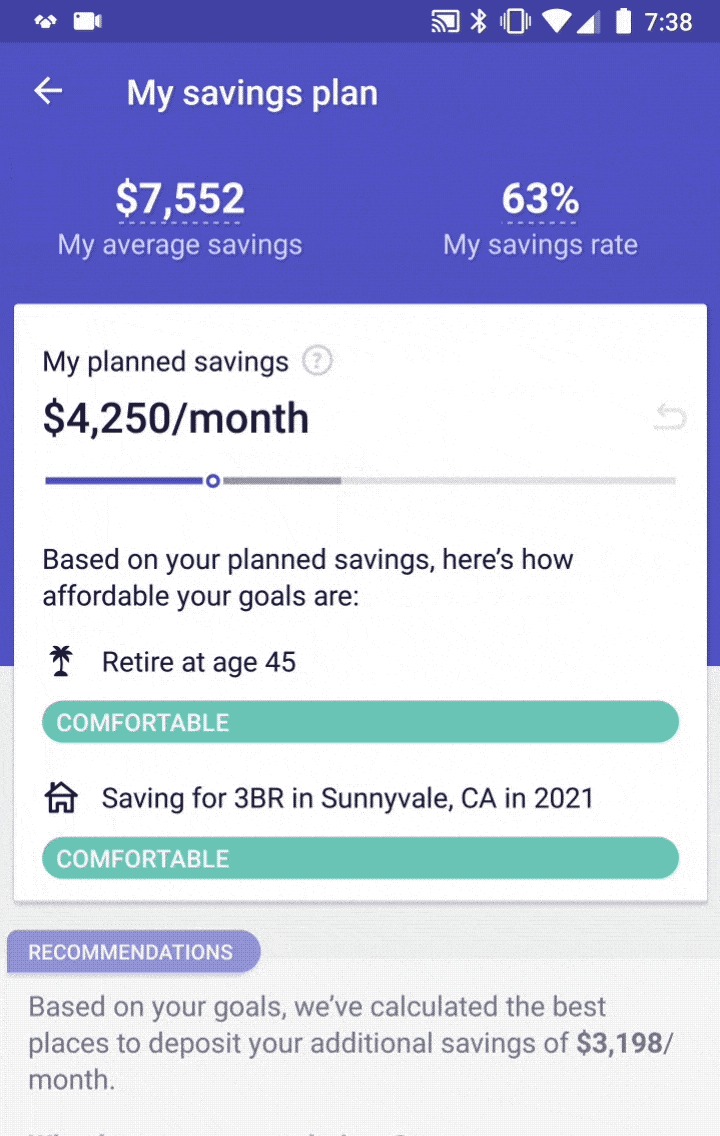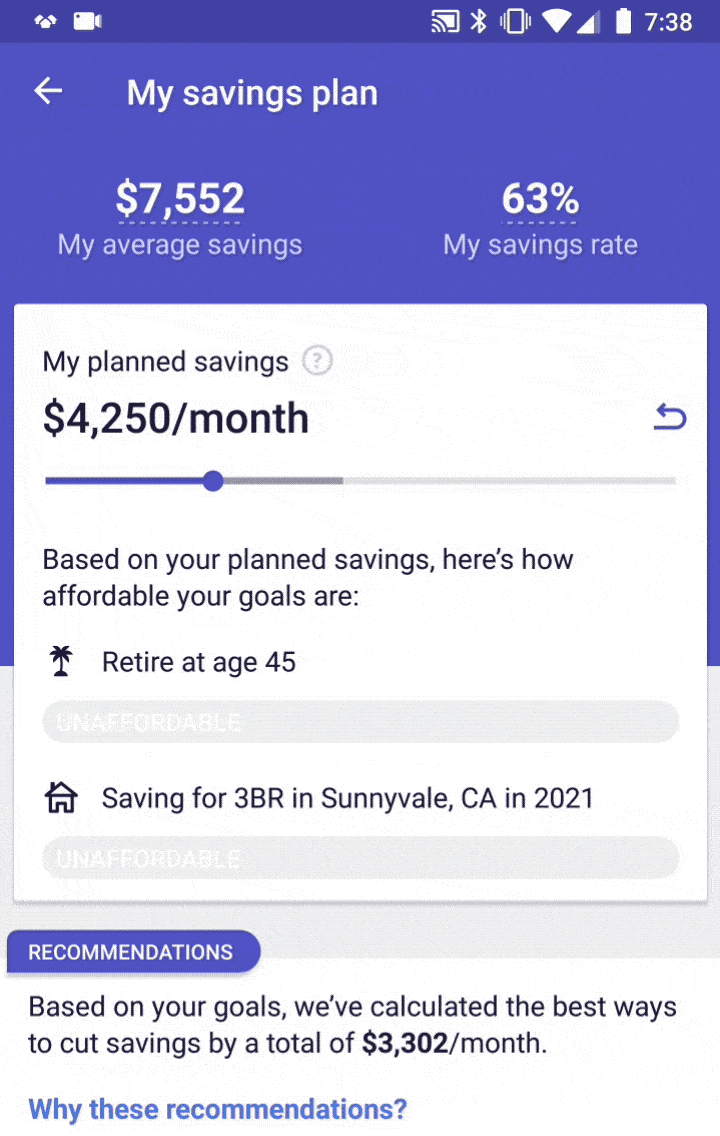
So, what goes into this GPS, and how do we make sure it’s functioning properly? To provide accurate advice on how to allocate your savings, we need to know:
- How much you intend to save
- What accounts you currently have
- Your goals
The algorithm
At a high level, the algorithm needs to synthesize these inputs into one coherent output – our recommendation of where to save by account. In Java, we can represent this with a Map from Account to Double, so our API looks something like:
Map<Account, Double> getSavingsRecommendations(
double savingsToAllocate,
Collection<Account> accounts,
Collection<Goal> goals);
Code language: Java (java)How do we arrive at this? For those who are curious and not allergic to a little math, here’s roughly how the algorithm works:
1) For each goal, compute the present value (PV1) of the cash flow(s) needed to fund that goal in the future.
2) Allocate funds we already have in our accounts towards the goals. If we allocate enough existing funds to match that goal’s PV, that goal is funded (meaning we don’t need to also allocate future savings to this goal).
3) Take the difference between the goal PVs and the funds allocated to each goal. Any goal with a positive balance remaining (a gap) are goals that we want to direct savings toward.
4) Use some fancy math (geometric series) to transform those gaps into the annual savings required between now and the time the goal occurs to bridge them.
5) Take our savings value and apply it toward the annual savings required for all the goals. If everything’s covered, put the excess toward retirement. If not, allocate the savings in such a way that the gap between the savings required for each goal and the savings allocated is relatively even across all goals.
6) Knowing the savings amount allocated to each goal, intelligently assign it to the most suitable accounts for that goal, recommending the creation of new accounts where appropriate. This produces a Map<Account, Double> for each goal. (This has its own set of complexities and pitfalls outside the scope of this blog post.)
7) Finally, merge the maps for each goal together. We now have our final overall savings recommendation map!
So that’s all well and good, but how do we gain confidence that we’ve done this all correctly? The last thing we want to do is recommend you put your money in a low interest savings account when what you need are the long-term returns of an investment account. Conversely, we actually do want to recommend putting money in that savings account if you have short term liquidity needs, such as buying a home in the next year. If you’ve read some of our other blog posts, you know that the answer to this question is automated testing.
Testing a complicated machine with multiple moving parts
At Wealthfront, our philosophy is to incur high initial fixed costs in exchange for near zero recurring costs by implementing fully automated testing for each change we push to production. We don’t have manual QA, and we don’t desire to employ manual QA in detecting whether our code functions as we expect it to. This allows us to release code to production multiple times per day without needing QA to sign off each time we push.
Writing fully automated tests for a piece of machinery as complex as our savings recommendation algorithm seems daunting. And why wouldn’t it? The exponential combination of possible inputs and outputs is massive, and, even with manual testing, we would run into the problem of how comprehensive we should make our test plan. If we try to test the machine like a black box, we gain little confidence that each piece within it is working correctly. We could just make all the intermediate methods package-private, which would allow them to be called directly within a test. But then we run the risk of exposing methods that should effectively be private to other classes within that package. A handy little annotation from Google’s Guava library solves this problem: @VisibleForTesting.
By annotating methods we want to test but don’t want to expose for use in other classes with @VisibleForTesting, we can preserve the encapsulation of these methods while also being able to test them and gain confidence they produce the correct intermediate output for a range of possible inputs. We enforce that methods annotated with @VisibleForTesting are only accessed in their own class or in tests by employing a MetaTest to check for this. If the test detects a violation, the build fails, and the code cannot be pushed to production until the issue is corrected.
public class AccountSavingsRecommender {
@Inject RetirementGoalSavingsAllocator retirementAllocator;
@VisibleForTesting
Map<Goal, Double> computePvByGoal(Collection<Goal> goals) {...}
……
@VisibleForTesting
Map<Goal, Double> allocateSavingsToGoals(
double savingsToAllocate,
Map<Goal, Double> savingsNeededByGoal) {...}
}
public class AccountSavingsRecommenderTest {
@Test
public void computePvByGoal_retirement() {...}
@Test
public void computePvByGoal_home() {...}
@Test
public void allocateSavingsToGoals_noSavingsToAllocate() {...}
@Test
public void allocateSavingsToGoals_excessSavingsToAllocate() {...}
}
Code language: Java (java)This also has the dual benefit of enabling tests to serve as the documentation of our code, describing specifically with asserts how the code being tested should behave in each scenario.
To mock or not mock
When unit testing complex pieces of logic that rely on the output of other separately tested pieces of logic, we prefer to avoid undue complexity in our unit tests and unnecessary re-testing by using mock objects. Mock objects allow us to declare exactly how the dependency code will behave and worry only about testing how its consumer will react to that intermediate output.
public class AccountSavingsRecommenderTest {
private final Mockery mockery = new Mockery();
private final RetirementGoalSavingsAllocator retirementAllocator = mockery.mock(RetirementGoalSavingsAllocator.class);
@Test
public void computePvByGoal_retirement() {
Account retirementAccount = TestAccountFactory.exampleRetirementAccount();
mockery.checking(new Expectations() {{
oneOf(retirementAllocator).getAccountForPvCalculation();
will(returnValue(retirementAccount));
}});
// rest of our test logic
}
}
Code language: Java (java)In the case of our recommendation algorithm, we inject classes that take care of figuring out what accounts to allocate to for a given goal (they handle step 6 above). It follows that, in our unit test for the algorithm, we mock these classes.
So, we’ve unit tested each piece of our algorithm thoroughly and used mocks to test it with a wide variety of goals and accounts. In spite of all that, when we started to verify whether the algorithm actually works for real internal users, we saw nonsensical outputs where the amounts of savings allocated to each account weren’t even adding up to the desired total savings. Certainly, we were asserting this basic constraint in our unit tests. Logging revealed that the account-level allocators were having problems working with the parameters they received from the overall algorithm, but it did not shed much further light than that. We needed the most valuable tool a programmer has in situations like this: the debugger. However, in the local testing environment where a debugger could be employed, we had mocked all the classes we actually wanted to dive into! (We can’t set a breakpoint inside a class being mocked since all a mock does is return a specified dummy value for a given set of parameters.)
(Component-level) Integration testing to the rescue
We’d encountered an uncommon scenario where unit tests alone had not given us sufficient confidence that our code works as intended. We needed something that could dig one level deeper and ensure that our algorithm and its dependencies interact in the way we expect. At the same time, we wanted to avoid all the overhead that comes with instantiating all of the infrastructure needed to serve a backend Path request – even in a lightweight test environment, this takes a substantial amount of time and would add costly seconds to each and every one of our automated builds going forward. Enter, the component-level integration test.
In practice, setting up an integration test for a component increases in difficulty when it is higher in module’s dependency tree. A component with eight layers of dependencies below it is likely to be fairly impractical to wire together by hand. As luck would have it, the class implementing our recommendation algorithm is fairly low in the tree with only three layers dependencies below it (and many of those sub-dependencies happen to be the exact same class). Here is a simplified version of how we wired the algorithm’s integration test:
public class AccountSavingsRecommenderIntegrationTest {
private static final LocalDate today = new LocalDate(2018, 6, 25);
private AccountSavingsRecommender getRecommender() {
AccountSavingsRecommender recommender = new AccountSavingsRecommender();
RetirementGoalSavingsAllocator retirementAllocator = new RetirementGoalSavingsAllocator();
retirementAllocator.today = today;
RetirementAccountSelector accountSelector = new RetirementAccountSelector();
accountSelector.setAccountTypes(ImmutableList.of(Type.R_401_K, Type.IRA, Type.TAXABLE, Type.EXTERNAL_BROKERAGE));
retirementAllocator.accountSelector = accountSelector;
recommender.retirementAllocator = retirementAllocator;
HomeGoalSavingsAllocator homeAllocator = new HomeGoalSavingsAllocator();
// similarly, wire the homeAllocator and the other goal allocators
return recommender;
}
}
Code language: Java (java)The other painstaking part of this process was creating test data complex enough to mimic the real-world user data that was causing the failure cases to happen. Our extensive use of the builder pattern in our codebase made this somewhat of a less onerous task:
Account realisticRetirementAccount = RetirementAccount.builder()
.withInvestedBalance(34_332.67)
.withCashBalance(2_190.95)
.withType(Type.R_401_K)
.withExpectedAccountReturn(0.057)
.build();
Code language: Java (java)With the algorithm and all of its dependencies wired together, we could now use the debugger to quickly spot what in the code was going wrong, rectify it, and make our unit tests more robust in the process. Everything was finally good in the world of savings recommendations… until a few clients began to write in saying they didn’t understand why we were recommending allocating their savings the way that we were.
Unravelling mysteries with the full power of Guice and json entity unmarshalling
One client in particular had a lot of retirement and college savings as well as a fairly aggressive retirement goals and numerous aggressive college goals for their kids. Despite this profile, we were recommending a savings plan that exclusively favored retirement. At first glance, this didn’t scream incorrect. Perhaps the plethora of college savings already covered their college goals and they did not need to save anymore. A few minutes with the calculator invalidated that theory. Maybe they were running into safeguards placed into the algorithm to prevent oversaving into a 529 account (in order to avoid penalties incurred from withdrawals for non-education-related expenses). This wasn’t the case either. An attempt to roughly recreate their case in the integration test failed to reproduce the issue. A cursory look at their profile indicated they had close to 20 accounts of myriad types – it would take a lot of time and effort to perfectly fake them in our component-level integration test.
At Wealthfront, we have another engineering principle that helps us decide how to proceed in situations like this: proportional investment. If we were going to spend hours of time recreating a case in an integration test to fix one bug, we should invest a similar amount of time in a solution that would prevent us from having to do this in the future. We quickly realized we could get all the parameters that define a particular client (including their account makeup) in json form as this is how our web and mobile clients communicate with the backend. Since all of our json entities are defined explicitly in code, we could then import these directly into our local java development environment. Finally, we would have to transform the raw json settings POJO into inputs that our backend Path projection logic could actually work with. The class that does this transformation is fairly high up in the dependency hierarchy, so here we finally decided to employ a heavier Guice integration test module that would wire all the dependencies we need (and many we probably don’t need) to save us the time needed to wire them by hand (as mentioned earlier, we create tests this way sparingly as they can add to our build time if we choose to include them in our testing suite).
With this additional testing infrastructure in place, we could now enter our savings recommendation algorithm as this particular client, put in some breakpoints, and eventually debug the issue.
Final thoughts
When generating extremely personalized advice using a sophisticated algorithm, we need that advice to be spot-on and error-free. In the future, this advice will enable us to achieve our vision to seamlessly route your money to the most appropriate accounts to achieve your goals. With clients trusting us now and in the future to provide this advice accurately, we have to test this component of our product as thoroughly as possible. By employing unit tests, component-level integration tests, and full-blown integration tests that can pass in parameters true to the complexity we find with real clients, we’re building confidence everyday that this mission critical piece of code is working as we intend it to.
If building the next generation of financial services products (like self-driving money™) employing test-centric development excites you, come join our team!
Footnotes
1. The PV of the cash flows required to fund the goal is equal to the amount the goal will cost today, multiplied by the rate at which the cost of the goal is expected to increase (compounded over the number of years until the goal), and divided by the compounded rate of return we expect from a typical account that will be used to fund the goal. (For example: if you intend to buy a 500,000 dollar home in 3 years, and we project the value of homes in that market to rise by 2% per year, and we invest for this goal with a low risk investment account expected to yield 4% per year, the PV of the goal will be 500,000 * e^(3 * [0.02 – 0.04]) = 470,882 dollars).
Disclosures
Path is a sophisticated personal finance model offered by Wealthfront that allows Clients to explore projections of various possible financial outcomes based on the latest data from their linked financial accounts, tolerance for risk, and current investments, as well as assumptions compiled by Wealthfront’s Research team.
Wealthfront and its affiliates do not provide tax advice and investors are encouraged to consult with their personal tax advisor. Financial advisory and planning services are only provided to investors who become clients by way of a written agreement. All investing involves risk, including the possible loss of money you invest. Past performance does not guarantee future performance.
Wealthfront prepared this blog for educational purposes and not as an offer, recommendation, or solicitation to buy or sell any security. Wealthfront and its affiliates may rely on information from various sources we believe to be reliable (including clients and other third parties), but cannot guarantee its accuracy or completeness. See our Full Disclosure for more important information.