At Wealthfront, we pride ourselves on reliable test coverage across our codebases. However, like many engineering teams, we haven’t been able to completely eliminate flakiness from our end to end (e2e) test suites. While migrating to puppeteer certainly helped, it didn’t eliminate the problem entirely. We’ll get into what causes these flakes below, but suffice it to say they are often complex race conditions that can be difficult to debug. Since we don’t want to block builds or deployments while we investigate, we decided to retry suites during the test runs, flagging the flakes for later investigation.
We use Jest to run our puppeteer e2e suites, and Jest has some good built in retry support. However, this retry logic only supports retrying individual tests and not full test suites. Since our test suites often look something like this:
describe(‘my e2e test’, () => {
// some initial steps
it(‘fills out a form and navigates to the next step’, () => { … });
// more testing
});
Code language: TypeScript (typescript)Retrying individual tests is often not effective. In the above example, we might not even be on the same page anymore when we attempt to retry the test! Instead, we need to retry entire test suites, which Jest doesn’t support out of the box.
Fortunately, we were able to write a short script that allowed us to retry entire suites easily and effectively, dramatically reducing the amount of failed test runs in the process. The below graph shows the percentage of successful and failed runs each day both prior to and post implementing the retries. A failed test run is defined as at least one test failing when all our e2e test suites are run.
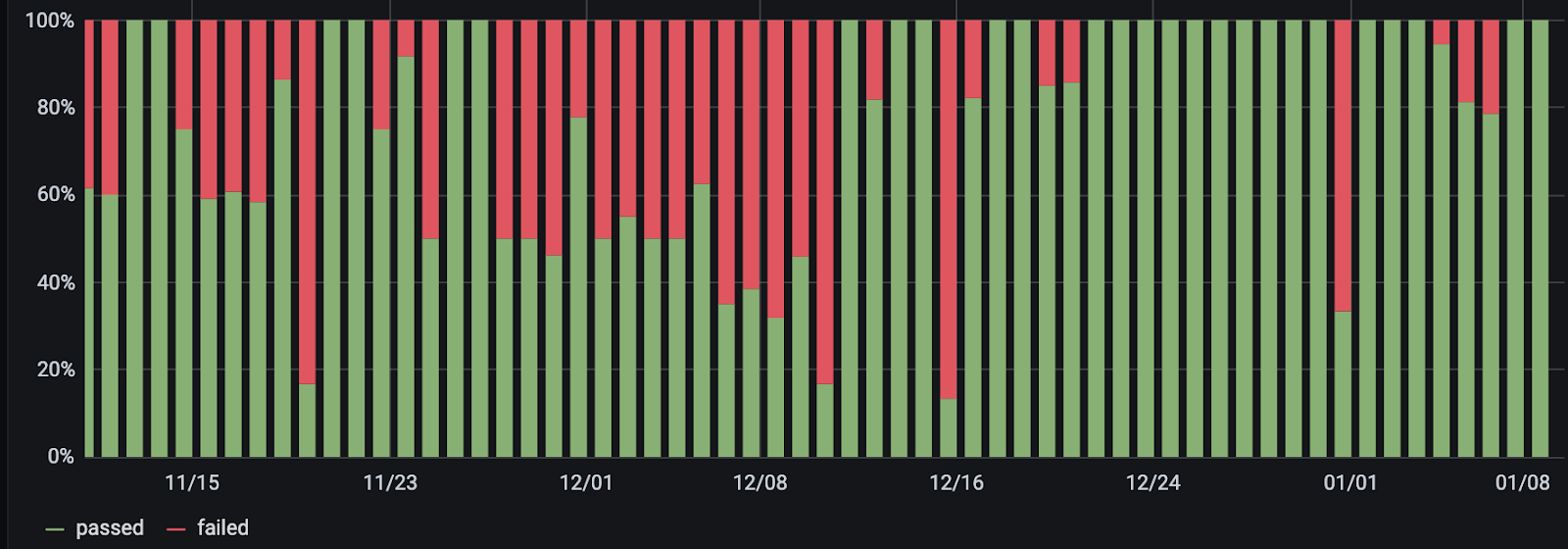
Why test suites
Before we get into how we retry our test suites, we should quickly address why our tests are structured this way to begin with. A logical question might be, “why not have each flow be tested by an individual test, instead of a suite where the individual tests represent various steps in the flow?” as this would allow us to utilize Jest’s built in retry logic.
The answer, in part, stems from how Capybara (a ruby based selenium wrapper library we used before migrating to puppeteer) prescribed tests to be structured and how we maintained much of that structure to ease the conversion process. However there are some distinct advantages to using this method as well. Namely, the benefit of having error reports quickly and clearly denote via the test name exactly where the test is failing, as you can see from this example error log:
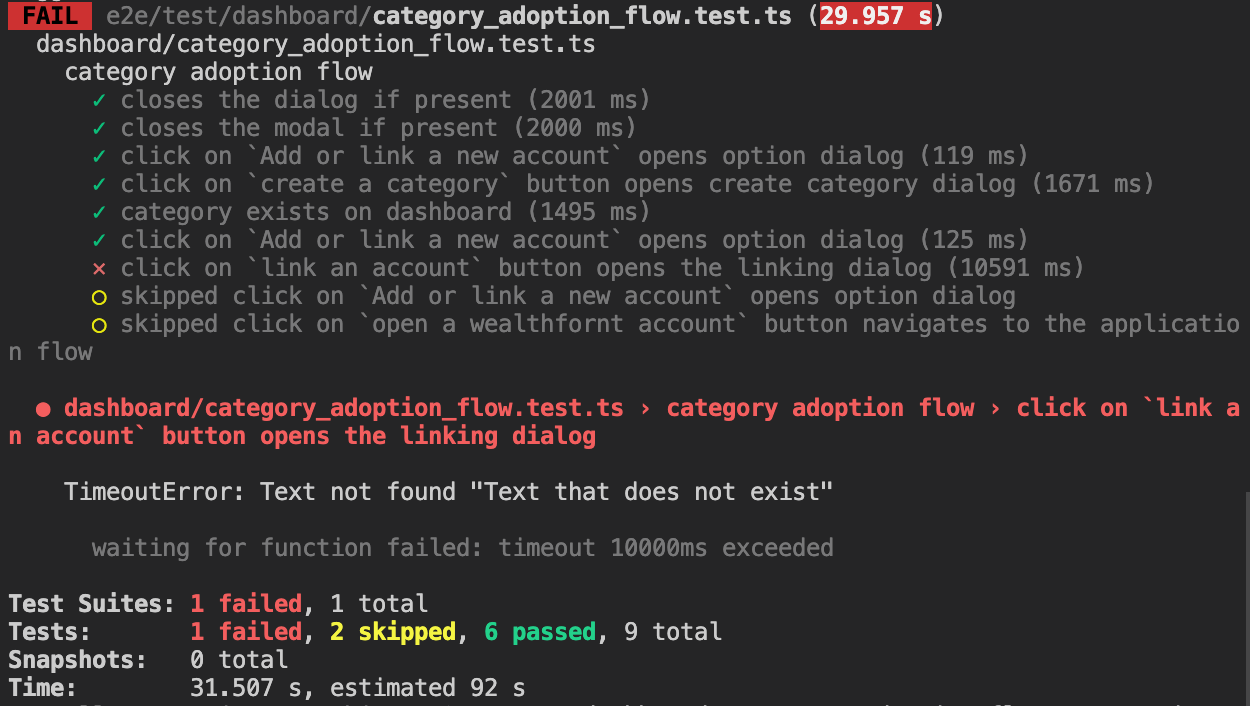
Many of these individual tests are also defined in shared helpers and reused across multiple test suites, which helps us to easily identify if one helper function is causing multiple suites to flake or fail.
Retrying test suites
The initial script to get the tests retrying was a bit more straightforward than we expected. All we needed to do was to run tests normally (via the command line tools), inspect the results for failures, and call Jest again, passing it only the failing tests. Keep in mind that since it’s just JavaScript, you can also import your existing configuration file as well.
// run_tests_with_retries.js
import { runCLI } from 'jest';
import jestConfig from './jest.config';
const NUM_RETRIES = 3;
async function runTestsAndRetry(jestConfig, retriesRemaining) {
const { results } = await runCLI(jestConfig, ['e2e/test']);
// If there were no failures or we're out of retries, return
if (!results.numFailedTests && !results.numFailedTestSuites) {
return Promise.resolve();
}
if (retriesRemaining === 1) {
return Promise.reject(new Error('Out of retries. Some tests are still failing.'));
}
// Compile a list of the test suites that failed and tell Jest to only run those files next time
const failedTestPaths = results.testResults
.filter((testResult) => testResult.numFailingTests > 0 || testResult.failureMessage)
.map((testResult) => testResult.testFilePath);
jestConfig.testMatch = failedTestsPaths;
// Decrement retries remaining and retry
retriesRemaining = retriesRemaining - 1;
console.log(`Retrying failed tests. ${retriesRemaining} attempts remaining.`);
return await runTestsAndRetry(jestConfig, retriesRemaining);
}
runTestsAndRetry(jestConfig, NUM_RETRIES);
Code language: JavaScript (javascript)Then any task runner (we use gulp) can call our new function. Alternatively, you can call the script directly from the command line or an npm script as well.
"scripts": {
"test-with-retries": "node run_tests_with_retries.js"
}
Code language: JSON / JSON with Comments (json)Managing JUnit results
For many, the above script may be enough. However if you’re like us at Wealthfront, you may rely on the JUnit output from Jest for parsing, storing and analyzing test results. Unfortunately, every time Jest runs, it will clobber the previous output. So retrying the tests will result in only the tests from the final run being reported. That means we’ll miss out on the data from all the tests that passed in any other initial runs!
To solve this, we can add some logic to our script that merges JUnit results as we go. Note that while we use JUnit at Wealthfront, you can modify this to support whatever test reporter you choose.
async function runTestsAndRetry(jestConfig, retriesRemaining, mergedResults) {
const { results } = await runCLI(jestConfig, ['e2e/test']);
mergedResults = mergeTestResults(mergedResults, results);
// configure jest-junit for our test run
const junit = new JestJunit(
{},
{
outputDirectory: './test-results/',
outputName: 'jest-puppeteer.xml',
}
);
junit.onRunComplete(null, mergedResults);
// ...
return await runTestsAndRetry(jestConfig, retriesRemaining, mergedResults);
}
function mergeTestResults(oldResults, newResults) {
// if it's the first run, we can just return the results
if (!oldResults.testResults) {
return newResults;
}
// make a copy of the old results so we don't mutate the input
const mergedResults = JSON.parse(JSON.stringify(oldResults));
// for each new result, input it in the old results alongside
// the previous result for that test
newResults.testResults.forEach((newResult) => {
const oldResultIdx = mergedResults.testResults.findIndex(
(result) => result.testFilePath === newResult.testFilePath
);
mergedResults.testResults.splice(oldResultIdx, 0, newResult);
});
return mergedResults;
}
Code language: JavaScript (javascript)This new function will merge the first run with the retried run by inserting each new test result adjacent to that test’s first failed run in the JUnit output.
You can also set the top level JUnit metrics in your merge function, although it’s worth noting that jest-junit doesn’t actually use the top level metrics, and instead sums the results of each individual test. Still, for completeness you can optionally add:
mergedResults.numFailedTestSuites = newResults.numFailedTestSuites;
mergedResults.numFailedTests = newResults.numFailedTests;
mergedResults.numPassedTestSuites = oldResults.numPassedTestSuites + newResults.numPassedTestSuites;
mergedResults.numPassedTests = oldResults.numPassedTests + newResults.numPassedTests;
mergedResults.success = newResults.success;
Code language: JavaScript (javascript)So now we have our test suites retrying and correctly outputting all the results, which is great. But what about the issues causing the flakes to begin with?
Flagging for investigation
Even though our tests are now retrying and hopefully passing successfully, our work isn’t quite done. It’s still important to investigate why the tests are flaking to begin with. Sometimes this can be caused by outages of other servers, especially if you’re relying on less stable development instances for your tests. There can even sometimes be network flakiness. However, e2e test flakiness is most often caused by bugs in the code! This is something I find to be commonly overlooked.
For example, in the Wealthfront account creation flow we navigate to new information gathering forms throughout the application process. If we move too quickly, something automated tests are certainly capable of, we can sometimes navigate to a new page before the data is fully updated on the server. A user navigating at a normal speed will rarely encounter this, however when automated tests speed through, they can sometimes get redirected back to a previous step that is assumed to be incomplete, thus breaking our tests. We’ve also seen some instances where a component will render, then enter a loading state, and then re-render once loaded. This flicker, typically imperceptible to humans, will often cause e2e tests to find elements in the initial render, but attempt to click only after it’s entered a loading state. While neither of these instances are major issues or user blocking bugs, they still indicate potential improvements we can make to our frontend code.
The main point here is that we shouldn’t ignore tests that flake, just because they pass on a retry. These tests are often highlighting real race conditions in our code. Fortunately, because we have good JUnit output from our merged results, we are able to parse and analyze the failure or flake rate of our tests. This allows us to make charts and flag flaking tests for review by the teams that own them, something we’d highly recommend you do as well.
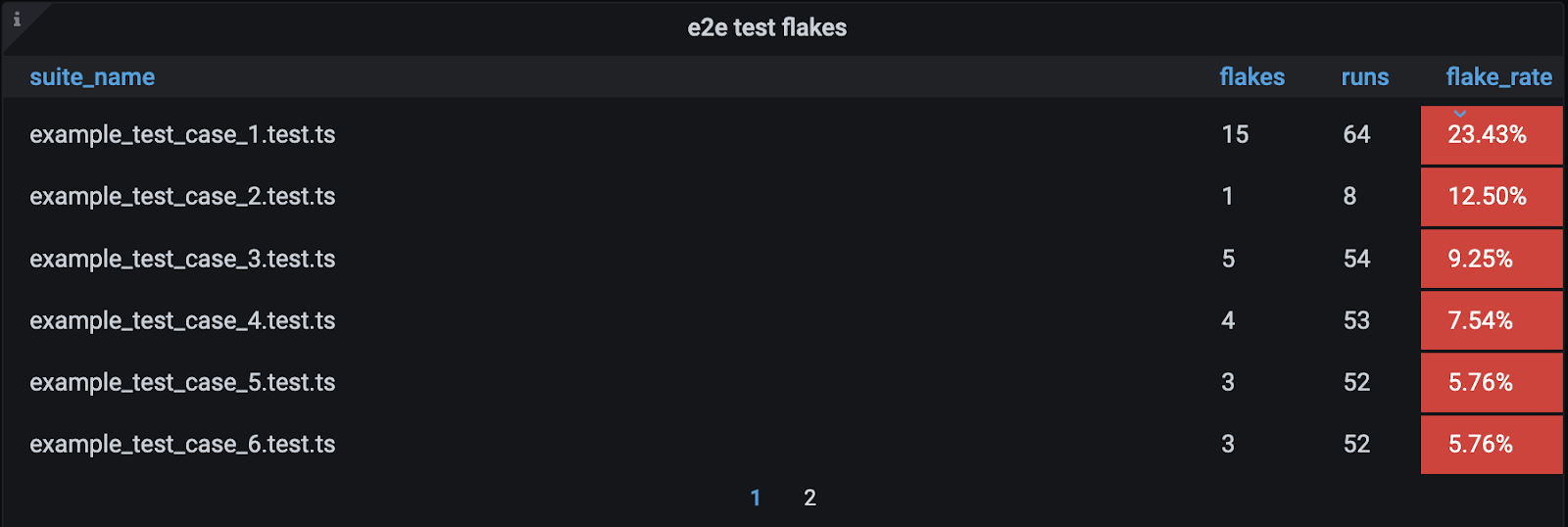
Conclusion
Good end to end tests may not always be the most alluring part of web development, but they are incredibly important tools in validating the reliability of complex software. Our e2e tests give us a lot of confidence in our production code. While retrying the tests is an incredibly valuable tool in helping improve build and development tooling, it is not a replacement for debugging the underlying cause.
If developing solutions to problems like these sound interesting, you want to help make it even better, or you want to generally help tackle the complex engineering challenges associated with building a financial system that favors people, not institutions, check out our careers page for current opportunities!
Disclosures
The information contained in this communication is provided for general informational purposes only, and should not be construed as investment or tax advice. Nothing in this communication should be construed as a solicitation or offer, or recommendation, to buy or sell any security. Any links provided to other server sites are offered as a matter of convenience and are not intended to imply that Wealthfront Advisers or its affiliates endorses, sponsors, promotes and/or is affiliated with the owners of or participants in those sites, or endorses any information contained on those sites, unless expressly stated otherwise.
All investing involves risk, including the possible loss of money you invest, and past performance does not guarantee future performance. Please see our Full Disclosure for important details.
Wealthfront offers a free software-based financial advice engine that delivers automated financial planning tools to help users achieve better outcomes. Investment management and advisory services are provided by Wealthfront Advisers LLC, an SEC registered investment adviser, and brokerage related products are provided by Wealthfront Brokerage LLC, a member of FINRA/SIPC.
Wealthfront, Wealthfront Advisers and Wealthfront Brokerage are wholly owned subsidiaries of Wealthfront Corporation.
© 2022 Wealthfront Corporation. All rights reserved.